Collecting and labeling data
Since October 13, 2020, we have been collecting tweets from Belgian users on topics related to the corona pandemic. We now have a dataset of 1.3 million tweets, so there are some cool things we can do with that.
We—ok, we delegated that task to job students—spent some time labeling a small set of these tweets. Half (53%) of the tweets are what we consider 'irrelevant', which is often the case for tweets from or about other countries or if there is no opinion. These irrelevant tweets are a small problem during labeling, because this means our poor job students spend time on tweets that are not relevant to us. To address this, we used a pipeline with multiple sieves that filter out some tweets at each stage.
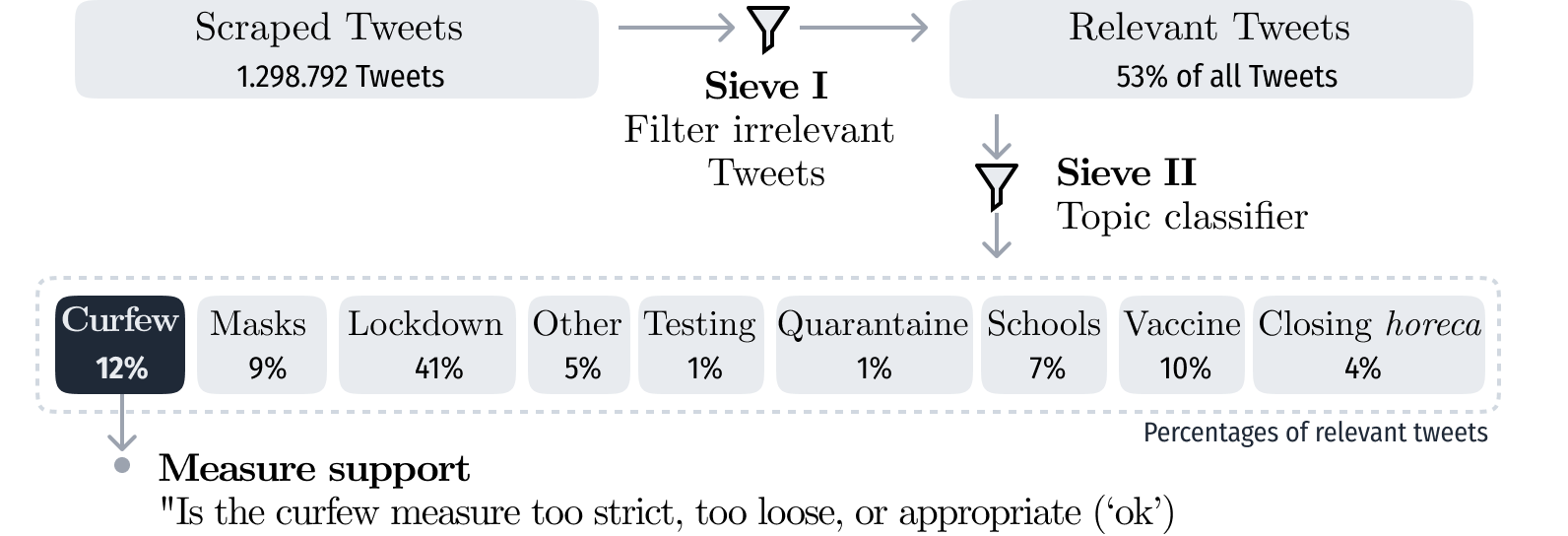
After filtering out the clearly irrelevant ones, we labeled the others following two axes: support for the government and support for the measures. We also kept the topic labeling. All labeling was done with Doccano, which works really well for our goal.
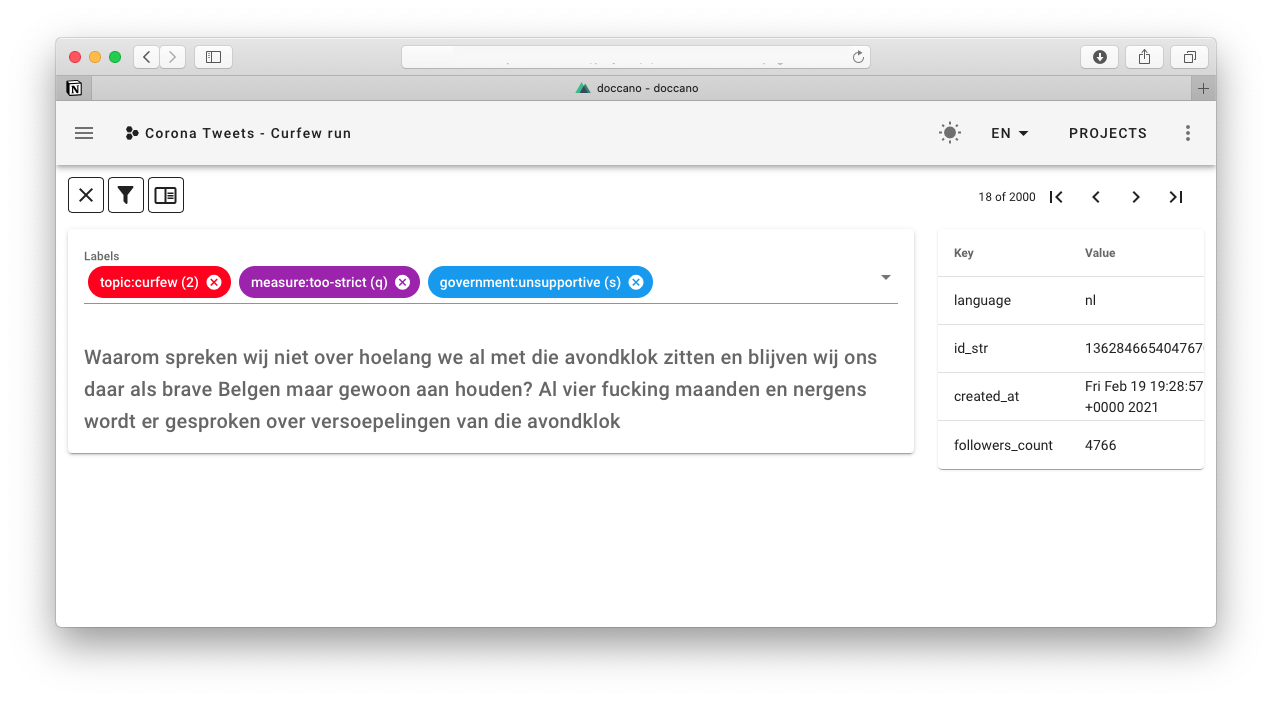
Based on these tweets and our labels, we created multiple BERT models to classify the tweets. Currently, our paper describes two models, which we also made public on the HuggingFace Repository:
DTAI-KULeuven/mbert-corona-tweets-belgium-topics: Multilingual (NL, FR, EN) BERT model to classify tweets into the following topics:- masks
- curfew
- quarantine
- lockdown
- schools
- testing
- closing-horeca
- vaccine
- other-measure
DTAI-KULeuven/mbert-corona-tweets-belgium-curfew-support: Another multilingual (NL, FR, EN) BERT model to classify the support for the measure that is expressed in the tweet, i.e.too-strict,too-loose,okornot-applicable.
What are people talking about?
With these models, we can analyze the entire dataset and see some cool patterns. We do see that people talk a lot about certain topics, like the vaccines when the first good news about that topic came out, and not necessarily the ones I care about (like the masks with my application What The Mask) or the schools.
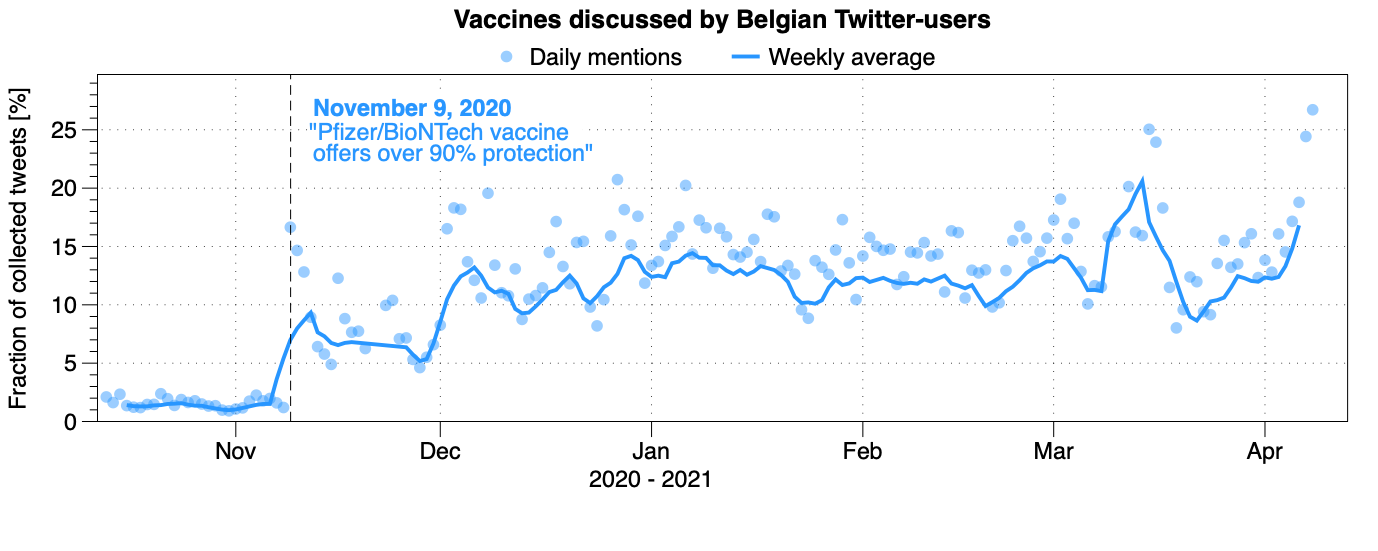
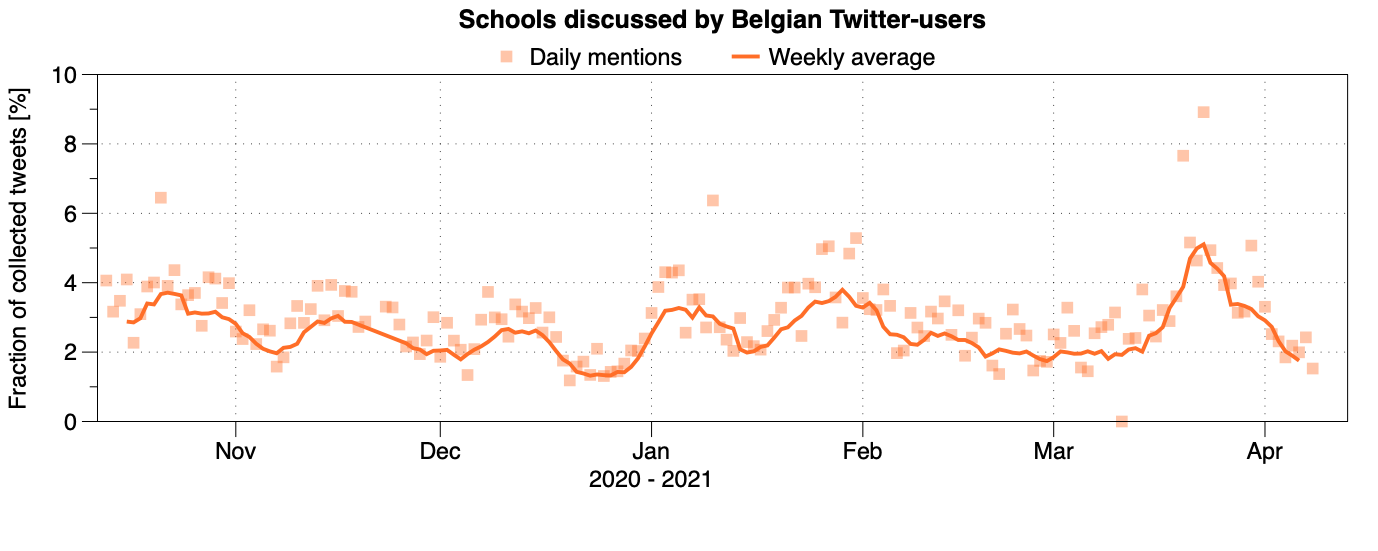
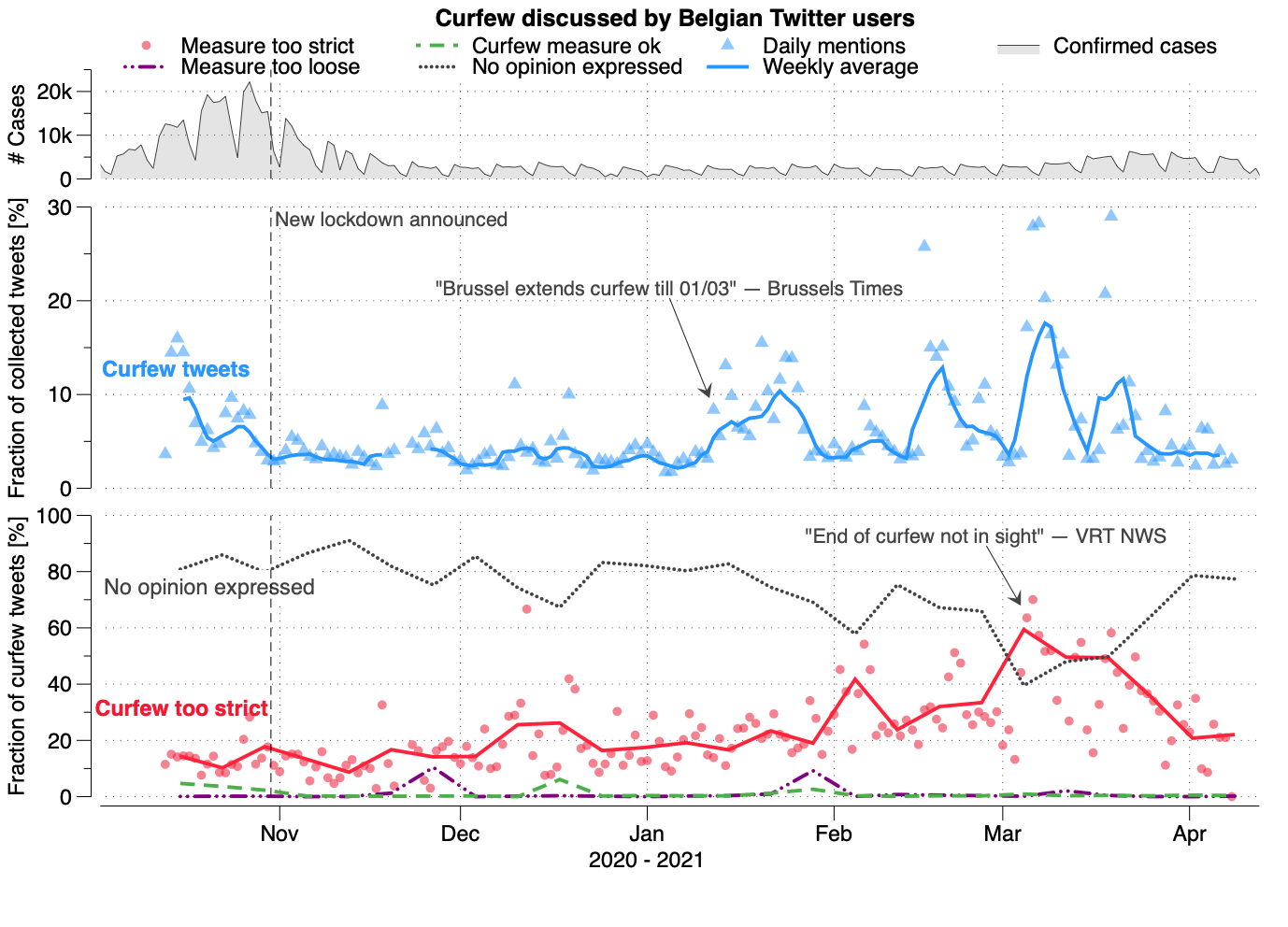
It's also really difficult to get a proper, meaningful signal from only a few tweets, so for the analysis of the support of certain measures, we focussed on the curfew. This is in part because the curfew—or rather curfews, since Brusssls, Flanders and Wallonia had different curfews—seemed to be a polarizing topic: either you support it or you think it doesn't work and should be abolished. So this gives some interesting opinions on Twitter, which we can use to track the support for it.
The curfews: not so controversial after all?
As it turns out, we overestimated the support that exists for the curfews; or at least the support that is expressed online. We see a constant number of tweets on the curfew which mostly are neutral (note that we have a really strict definition before a tweet is not neutral anymore) with some spikes following media attention. As we left the second wave, the fraction of tweets that thought the curfew was too strict grew. Only at the third wave the opinion shifted again, with media repeating that we'll be stuck with the curfew a little while longer.
Try it yourself
If you like these kinds of analysis, you can also do this yourself. We made our models available and the code to scrape the tweets is on our github repo. And you can read the paper if you want to know more!