The need for a new RobBERT model
2020 happened. RobBERT was trained in 2019, so some terms have since then changed meaning—corona is no longer just a beer—and new words are now in common use. RobBERT doesn't know about all of this.
The new dataset
The OSCAR corpus has a new 2022 version, which we can use for our project. However, the data is packed a bit differently. The version of OSCAR that we used previously was "shuffled", meaning that only a few sentences of a document were kept together instead of the entire document. This worked pretty well to train RobBERT on, but might not really learn longer-ranging dependencies because of this.
We previously looked into the shuffled and non-shuffled variants of the corpus when we trained our distilled RobBERTje models, and we found that only some tasks benefit from longer training inputs. But more importantly, merging different training examples also reduced the training time, since we make more optimal use of the 512 tokens we can provide to the model compared to using only single lines (typically 1 or 2 sentences, but can also be one word).
The new corpus uses a slightly different format and provides the entire documents, leaving the shuffling to us if we want it. This is pretty nice, because that means we can train on entire documents, as long as they are below the 512 token limit.
To get a better understanding of our dataset, I've plotted the distribution of the document length. With single lines, the inputs are really short, 80% is shorter than 35 tokens. For entire documents, we need 315 tokens to cover 80% of the documents. That's a big difference...
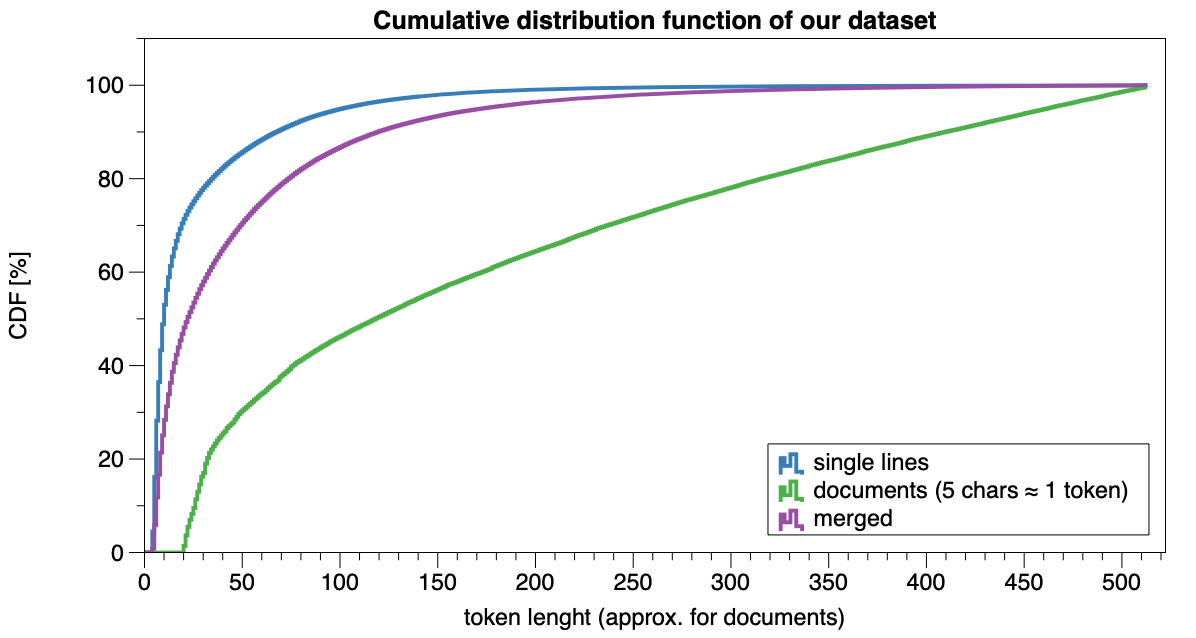
I've also included the merging algorithm that we used for our distilled RobBERTje models. This is a bit more spaced out, but not a lot.
The benefits of training on the entire documents are (i) more examples long-ranging dependencies, (ii) better use of the maximum number of tokens and (iii) the model actually learns to use line breaks as well.
Training on entire documents it is!
Updating the tokenizer
Retraining our model on a new dataset is all fine and well, but a few
things happened since 2019 that also affect which words we use. Words
like corona or COVID were not in the original
tokenizer for obvious reasons. But we started using those words quite a
lot.
So we also want to add some tokens to our vocabulary. For this, we can create another BPE tokenizer and look at which tokens are new (notebook ). This is pretty cool, since it also gives us some more insights in what words society started using, for example:
- coronamaatregelen
- coronaregels
- coronacrisis
- coronat
- coronab
- coronabesmettingen
- corona
- Bitcoin
- Biden
- omikronvariant
- TikTok
Since we use merges of two different tokens, like
coronab with something else`, we do also want to add those
to our tokenizer. This is a bit trickier. Each token namely has a
"dependency tree" of other tokens and each time they are
merged. As an illustration, these are the final merges of three
tokens.
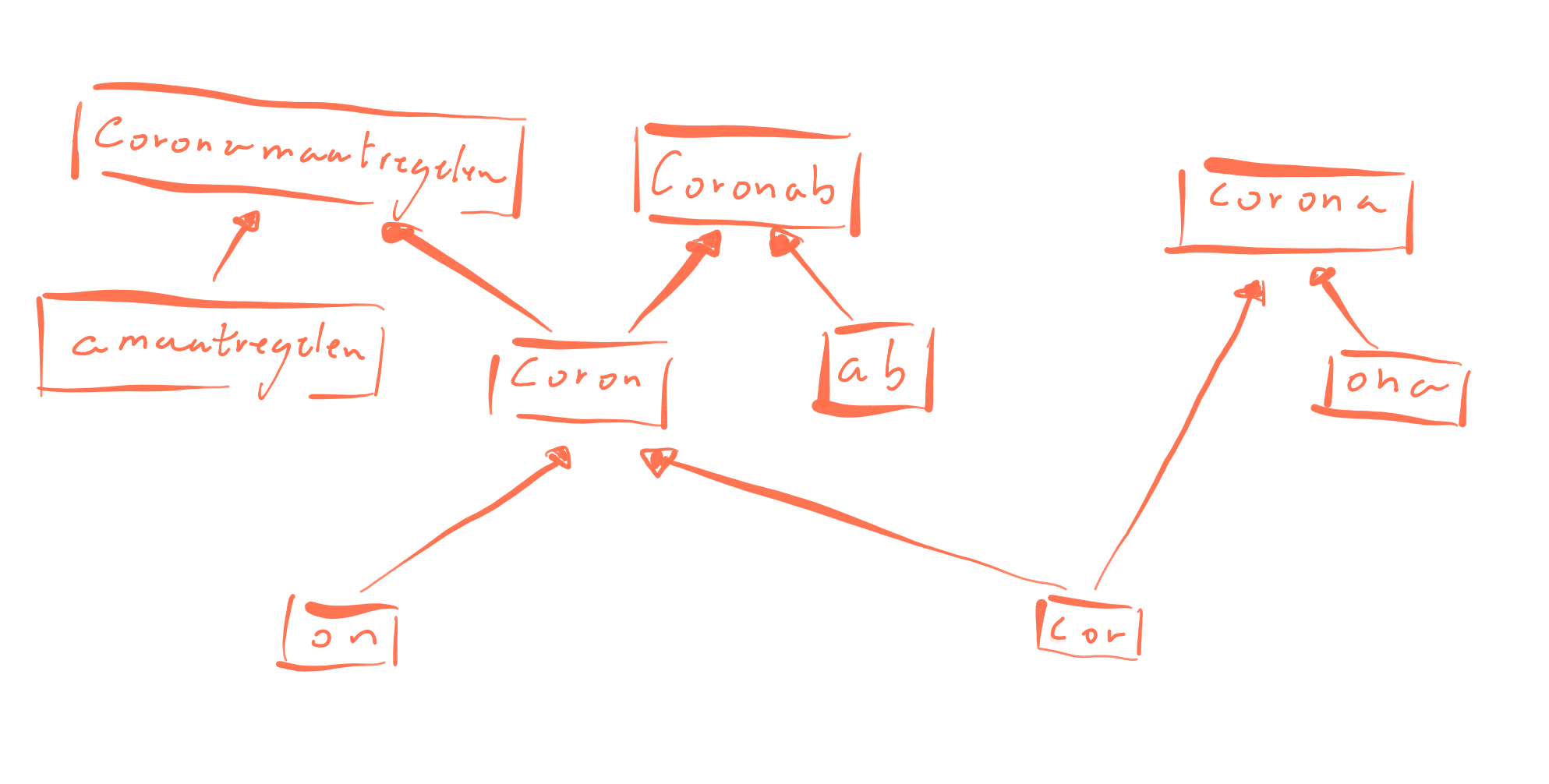
Because this is a statistical process, some merges make little sense, especially in Dutch where we have compound words. We had a thesis student working on improving these merges, but that is quite tricky to automate.
To extend our RobBERT vocab, we can add all the new tokens. Since we
can view both vocabularies as sets, the difference
New - Old will have all the tokens and by definition also
the dependencies that were not in the old tokenizer to begin with.
But we still need to figure out how to find the merges. We only need
the merges that result in a token that is in the difference
New - Old, since all others should be covered by the
original RobBERT (v2) tokenizer. This means we can easily iterate over
all merges, perform the merger and check if it is one that we need.
So that gives us a new vocabulary size of 42774, meaning we added 2774 tokens. The actual difference was a bit larger, but I removed some completely meaningless ascii sequences. If we are performing tokenizer surgery anyways, why not do it right?
For tokens related to corona or other things after 2022, this is obviously a big improvement:
>>>tokenizer_2022("De coronamaatregelen")
[0, 62, 42162, 2]
>>>tokenizer("De coronamaatregelen")
[0, 62, 8913, 265, 564, 856, 20959, 2]The actual training
To train our model, we have a few options that affect our performance and more importantly, total training cost. First, we could train the model from scratch like we did when transitioning from RobBERT v1 to RobBERT v2. Second, we could continue pre-training. Third, and perhaps the most out-of-the-box method would be to distill our RobBERT v2 model to a smaller "RobBERT(je?) 2022" model, which would be challenging with the different tokenizers.
The reason that I spend all the effort extending our vocabulary, is because we can also size up our embeddings matrix in RobBERT, without losing the existing embeddings. This means that we can use the 40k embeddings we already have and just have to train for those 2774 new tokens. Ideally, this would also make the embeddings somewhat compatible, but that is speculation.
The hyperparameters are pretty standard. The MLM probabilities are
10% replacing with a <mask> token and 10% with
another token. We use gradient accumulation over 128 batches for an
effective batch size of 2048 with 2 3080 Ti's.
The model is now training, so fingers crossed that it is actually an improvement...
What's next?
Hopefully this model will perform pretty well tasks with more current language usage and by training on enough data, it hopefully won't suffer from catastrophic forgetting.
If this is the case, you might see a paper appearing. Otherwise, I guess RobBERT 2022 stops with this blogpost.. 🤷♂️