To evaluate how good LLMs are, we typically use a large set of benchmarks. To do this, EleutherAI has (in collaboration with HuggingFace) built a LM Evaluation Harness, which works really well for English. But for Dutch, we have fewer options.
Although there are quite a lot of tasks (NER, POS, sentiment analysis, ...) and even the DUMB benchmark for MLMs, there are still not many options for causal language models like GPT.
SQuAD is one of the few benchmarks that has a Dutch counterpart (SQuAD-NL) and is included in the Evaluation Harness. To get a sense of what the existing Dutch models can do, let's run them on SQuAD-NL with 0-shot and few-shot tests.
All evaluations were done using iPieter/dutch-lm-evaluation-harness/commit/63fb2f.
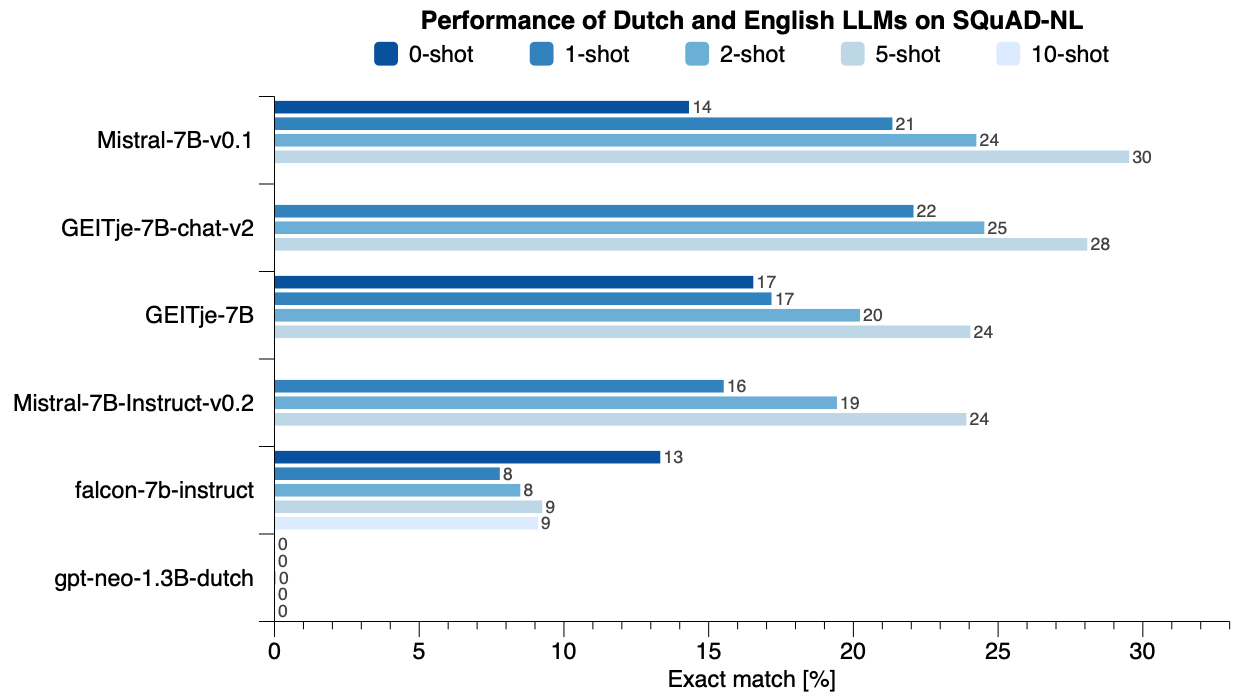
If you came here for the raw numbers, that's it: Mistral-7B-v0.1 and GEITje-7B-chat-v2 perform best with GEITje being better for zero-shot and one-shot QA.
However, those numbers are not the only useful thing we can learn from these tests. Let's take a look at some responses.
Zero-shot performance
yhavinga/gpt-neo-1.3B-dutch
- exact: 0.0000%
- f1: 1.4668%
The performance of this model is not great, but that is mostly because the model is not answering any questions as it's not trained on that. To give an example:
Context:
Jaarlijks vinden er verschillende herdenkingsevenementen plaats. Bijeenkomsten van duizenden mensen aan de oevers van de Vistula op midzomernacht voor een festival genaamd Wianki (Pools voor kransen) zijn een traditie geworden en een jaarlijks terugkerend evenement in het programma van culturele evenementen in Warschau. Het festival vindt zijn oorsprong in een vredig heidens ritueel waarbij maagden hun kruidenkransen op het water lieten drijven om te voorspellen wanneer ze zouden trouwen en met wie. In de 19e eeuw was deze traditie een feestelijke gebeurtenis geworden, en het gaat nog steeds door. Het stadsbestuur organiseert concerten en andere evenementen. Elke midzomeravond zijn er, afgezien van het officiële drijven van kransen, springen over vuren, op zoek naar de varenbloem, muzikale optredens, toespraken van hoogwaardigheidsbekleders, kermissen en vuurwerk langs de oever van de rivier.
Vraag:
Naar welk type bloem wordt gezocht op midzomeravond?with two correct answers de varenbloem and
varenbloem that are explicitly in the text, that should be
easily answerable. However, this model just responds the following:
De bloemen die op midzomeravond worden gevonden, zijn de bloemen van de midzomeravond. De bloemen van de midzomeravond zijn de bloemen van de midzomeravond.That's not bad, since it is a newly formed sentence (twice). But for SQUAD, that doesn't count.
Rijgersberg/GEITje-7B
- exact: 19.0000%
- f1: 25.5116%
That's a lot better already. On the same example question as before, we now get the following answer:
VarenbloemDon't worry about the upper case V, the responses get
normalized before computing the score.
Rijgersberg/GEITje-7B-chat-v2
- exact: 12.4042%
- f1: 24.1226%
Some responses, like the Varenbloem are also correct.
But sometimes the model is tempted to answer with longer sentences than
strictly needed:
'Wanneer wordt het Wianki-festival gehouden?', 'answers': {'text': ['midzomernacht'], 'answer_start': [132]}}Het Wianki-festival wordt gehouden op midzomernacht, 23 juni.mistralai/Mistral-7B-Instruct-v0.2
- exact: 6.0000%
- f1: 17.0848%
Mistral has the same problems as GEITje-chat, which is not surprising since GEITje is based on Mistral. A bit lower performance seems to be caused by less natural Dutch, for instance in this question:
Waarvan zijn er veel in Warschau?The correct answer is evenementen en festivals, but
Mistral gives something kind-of-correct (ignoring the added period),
Muziekgebeurtenissen en festivals.