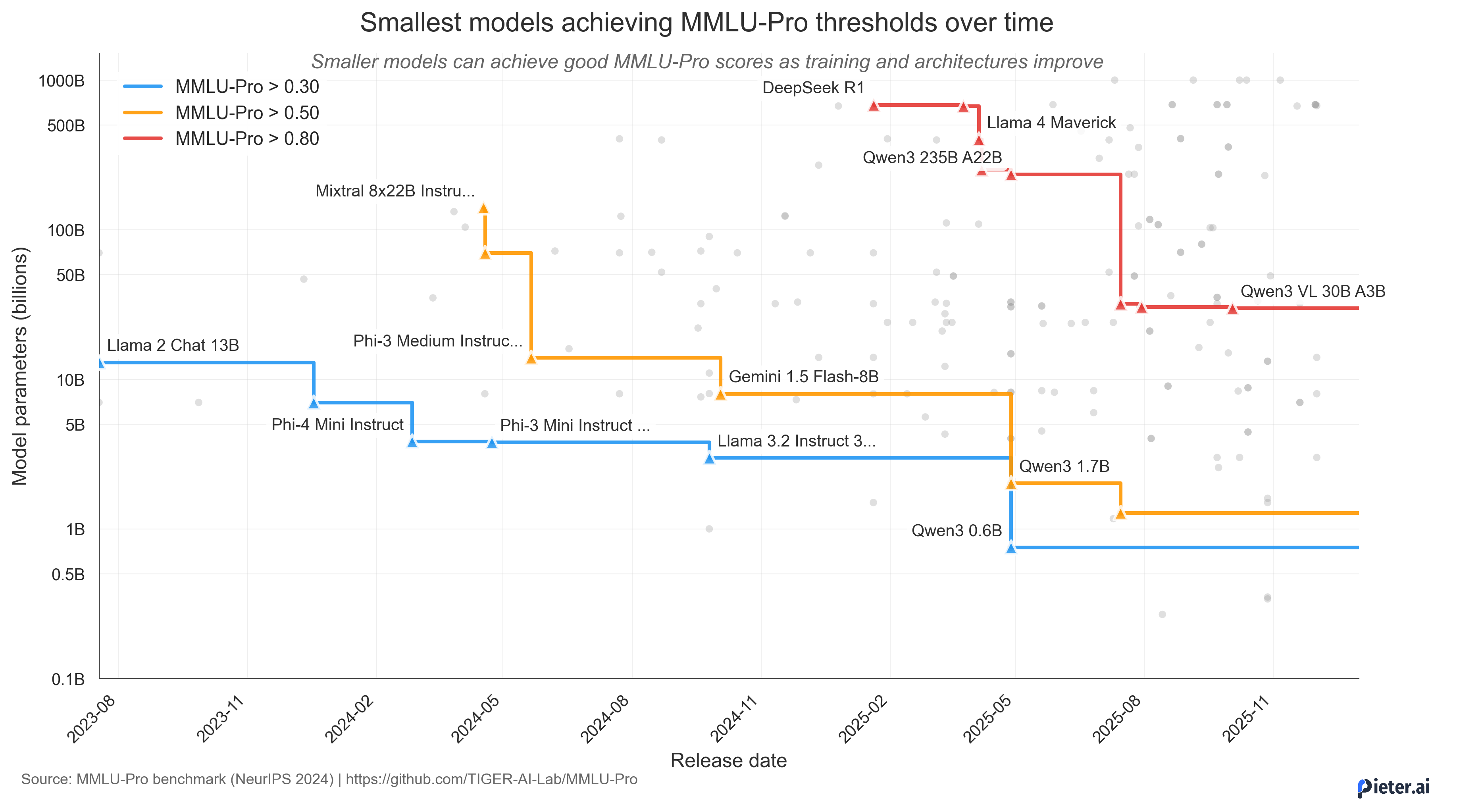
We have exceptionally good open-source large language models that came out in 2025: models like DeepSeek R1 perform well on a wide range of tasks in many languages. This model’s release in January was one of the highlights of 2025. It crushed evals, woke up investors, and was unusually transparent about their insanely profitable deployment setup[1].
With almost 700B parameters, though, DeepSeek R1 (or V3) cannot be hosted economically unless you achieve sufficient scale. And sufficient scale is not to be underestimated. For example, you need to maintain 4k concurrent requests on a GB200 NVL72 to get sufficient economies of scale[2]. 4k Requests continuously; no matter the time. Below that, the 3 million Euro you spent on that cluster is just not worth it. So for many organizations, large frontier models just can't be self-hosted economically.
Luckily, smaller models have become more capable in 2025. While they are not on the level of DeepSeek R1, we do see a trend where the number of parameters needed for a given MMLU-pro score drops by roughly an order of magnitude each year.
If you saw the LLMflation chart from a16z[3], you can consider the above chart as the (mostly) open-source equivalent. Fewer model parameters make a model easier to host by inference providers, so--all things equal--this should result in cheaper tokens.
But more importantly, below certain parameter sizes, hosting a model becomes qualitatively different. To use some LLM rethoric: It’s not just “we need one less GPU”, it's a whole new way of hosting models. As an example, you can now host a model as capable as Mixtral 8x22B (from April 2024) with a 1.7B model on your smartphone. Even with mixture-of-experts, you still need over 200 GB of VRAM for the Mixtral model, so hosting that will require a few H100s or an AMD MI350 if that's your thing. Either way, 1 kW of power for hosting a 2024 model that is as capable as one from 2025 that runs on a device with a battery.
I believe this is a big modality shift that will happen soon-ish and might already have happened at frontier labs (OpenAI’s o1 being rumoured to be an 8B model for instance). Many smaller language models are already quite capable, albeit in only a smaller domain or language. Since their capabilities will only increase, there will be a point where many people will be happy enough with a model that can run locally, especially for simple or medial tasks, for instance a slightly smarter Siri.
Synthetic data pipelines are another trend we saw emerging in late 2025 that is favorable for small models. Whether you use it for RL’ing or post-training models or for Baguettotron[4]-style training on fully synthetic data, we see in both cases that high-quality synthetic data can close much of the gap between smaller models and their larger counterparts. In the case of Baguettotron, it even enabled a model with 0.3B parameters to have instruction following, reasoning and decent memorization. Such innovations drive down the cost of making task-specific models, for instance for code completion or customer chatbots.
Why would we want sovereign AI?
Before diving into the technical details of small language models, let's first focus on why I think that ChatGPT, Claude, and Copilot will not be a panacea.
I am based in Europe, and with the current geopolitical evolutions, I spoke with many organizations are at least a bit hesitant to rely on external, commonly, US inference providers. Chinese providers, like DeepSeek, are completely unacceptable due to data privacy concerns. Confidentiality and enterprise guarantees are often mentioned in my experience. These concerns are not absolute and contracts can mitigate a lot. Microsoft has an edge here, as they bundle some Copilot variant with existing Office products and have a foot in the door with existing contracts. Nevertheless, the far-reaching access of US agencies to EU-deployed services[5] might be off-putting for some organizations.
As an alternative, European inference providers could emerge. Companies like Mistral—and to a certain extent, my previous employer, Aleph Alpha—do manage to get a foot in many European doors: they start providing their own GPU datacenters, their own models and their own stack of tools (like Mistral Vibe CLI). But many companies already have contracts in place with American providers, for instance Microsoft for Teams and Office which covers Copilot. Therefore, new vendors have an uphill battle with those existing contract,s fighting with procurement, security review, legal, etc. But an internal team self-hosting a small model can often bypass that entirely, operating within existing infrastructure. This hinges on models that are good and reliable enough, as well as flexible inference options; two fronts that are actively evolving.
That evolution is already underway: there is once again a shift towards more tailored models, this time powered by RL. As we'll discuss in the next section, RL and synthetic data make specializing small models cheap and the tailored models that result don't need to be exceptionally large. As a consequence, self-hosting or local inference becomes more feasible.
Small language models are quite capable in specialized domains and offer nice inference characteristics for on-prem deployment, as well as the data security that many European orgs do care about. With $0 extra expenditure on hardware, many small or medium orgs can now deploy some models that truly work for their daily work and don’t rely on external providers. That sounds sovereign to me.
Training and inference
Hosting tailored language models is still a trade-off. At this moment, there are basically only three options:
- spend a lot of money for a hosting setup that is underused,
- use LoRA and co-locate your underlying model with different orgs,
- select a small enough model that you can host economically (e.g. on a Macbook).
I believe the third option is the most sensible approach. We already saw an explosion of SFT’ed models, and RL will only make this easier.
Small language models do exist, but there is still a large gap between the performance of, e.g., Qwen-0.6B and DeepSeek R1 with 680B parameters.
Synthetic data can bridge this gap. While large language models have a lot of emergent abilities that are desirable to have, a lot can also be distilled back into small language models, as demonstrated by DeepSeek’s R1 distill series (1.5B, 7B, 8B, 14B, 32B, 70B) and Baguettotron with their compact reasoning traces. While not exactly the same, these reasoning traces are quite decent, and we do see these models perform well already.
We don’t develop models in a vacuum: capable large language models exist that can be leveraged for synthetic data generation, providing good reasoning traces and domain-specific environments. As Piotr Mazurek argued[6], we will increasingly see tailored models built in specialized RL environments. I suspect this will often be a one-off cost to create an in-house environment to train models in.
The base models themselves are not necessarily that special. While there are interesting trends in training these models, the best permissively-licensed model at your desired size can be adapted for the task at hand with relatively little effort. The base model is a starting point, not the product.
Once you have good enough small models in one domain, some RAG or tool calling to ground the model and a deployment environment that makes usage easy, I think we will see an explosion of these models.
This all relies on having an easy-enough training pipeline. Productized on-prem finetuning is extremely difficult for larger models, my previous employer even hosted a public talk about this[9]. While there are innovations in the finetuning or RL’ing infrastructure, like Tinker from Thinking Machines, these focus mostly on centralized training. Again, here small models have an edge since training is so cheap and requires very little hardware, which enables on-prem training. This also lowers the expertise barrier: a single ML engineer can handle the pipeline for a sub-2B model, and for organizations without in-house ML talent, the cost is low enough to outsource as a one-off engagement; the RL environment and data carry over between base model generations.
On the inference side, “edge devices” are becoming more capable of doing local inference. An entry-level MacBook Pro M4 costs less than $2k and can run Baguettotron with 80+ tokens/sec in a typical chat+RAG context. This is more than acceptable for most use cases and offers all the benefits of local inference (data and chat privacy, reliability regardless of network, …).
Local hardware also opens up test-time scaling. Running a few samples in parallel barely affects throughput on an M4. Since the prompt prefill is shared across samples, best-of-n or more complex sampling strategies could improve performance a lot for little cost.
Model deprecation
One risk with developing custom models is that they are outdated with the next release of GPT-x or Gemini y. I do have some personal experience with this: we trained ChocoLlama[11], a Dutch model, starting from Llama 2 and Llama 3 surpassed our finetuned model. But we also did invest efforts in our dataset and SFT’ing Llama 3 surpassed it again. Smaller capable base models, RL environments, and high quality (synthetic) data all lower the cost of a quick deprecation cycle. If you can download the last model, RL it on your tasks and deploy it once a year for less than € 1k, why wouldn’t you? At roughly €1.50/h for an H100, even 500–1000 GPU hours of RL for a 1B model lands at $750–1500 in compute. A very reasonable budget, especially if the pipeline and RL environment carry over from a previous iteration.
Deploying models matters just as much as training them. The best way to improve models is still to get usage patterns that can be incorporated in the next iteration. Models might perform well in custom environments based on internal data lakes, but those environments need to match what people use them for. The smaller the model, the more it matters to be in-domain. So your domain needs to match, and user feedback helps with this.
So what's next?
As we see model capabilities increase on the frontier with large, approaching 1T sized, models, we also saw capabilities increase for smaller models. Equally capable models have been shrinking in parameter count. As we argued in this post, this allows for easier deployment to the point that something decent can run on your Macbook.
For European organizations, that matters. US and Chinese cloud providers come with real concerns, and switching to a European vendor means procurement, security review, legal sign-off. A small model running on existing hardware sidesteps all of that. Synthetic data and RL make it possible to specialize that model for your domain cheaply. And when a better base model comes out, you RL it on your tasks and redeploy. All in all that's less than € 1k, perhaps once a year.
That's not to say that there is no value in the large frontier models. I personally also use Claude Code like the rest of us, but for many tasks this 'frontier intelligence' is not needed. There are many occupations that benefit from some LLM-assisted processing already, and for most of those a small, locally-hosted model can do the job. The pieces are there. What's missing is making the tooling and workflow easy enough that teams actually use it.
References
- DeepSeek, “DeepSeek V3/R1 Inference System Overview”, GitHub. ↩
- Piotr Mazurek and Eric Schreiber, “MoE Inference Economics from First Principles”, Tensor Economics. ↩
- Guido Appenzeller, “Welcome to LLMflation – LLM inference cost is going down fast”, a16z. ↩
- PleIAs, “Baguettotron”, Hugging Face. ↩
- Molly Quell, “Trump’s sanctions on ICC prosecutor have halted tribunal’s work”, AP News. ↩
- Piotr Mazurek, “AI Infrastructure in the Era of Experience”, Tensor Economics. ↩
- Cursor, “Composer 2”, Cursor. ↩
- Cursor, “Real-time RL for Composer”, Cursor. ↩
- Aziz Belaweid, “How to Build an On-Premise LLM Finetuning Platform”, Aleph Alpha. ↩
- Ljubisa Bajic, “The path to ubiquitous AI”, Talaas Inc.. ↩
- Matthieu Meeus, Anthony Rathé, François Remy, Pieter Delobelle, Jens-Joris Decorte, Thomas Demeester, “ChocoLlama: Lessons Learned From Finetuning Llama for Dutch”, arXiv. ↩