
Today we release Nemotron-Personas-Belgium together with NVIDIA: a synthetic dataset of 4 × 300k Belgian personas in Dutch, French, German and English, openly licensed (CC BY 4.0) and announced on the Pleias blog.
- Pleias: NVIDIA Nemotron-Personas-Belgium, the Pleias announcement of this dataset.
- France advances Europe's AI future with NVIDIA, NVIDIA's take on the wider sovereign-AI effort.
This was a fun one to lead. Belgium is small, multilingual, and politically complicated in ways that show up immediately when you try to build a representative dataset for it.
Why personas, and why grounded ones
Synthetic data is becoming a load-bearing part of LLM training, but generating diverse synthetic data is hard. Models tend to collapse onto a handful of templates. Personas are one way to inject controlled diversity: you give a model a believable, specific person to write as, and you get text that varies along the axes that real-world variation actually runs.
The trick is making the personas representative. A persona dataset that's secretly 80% software engineers in Brussels doesn't help you. So we ground every persona in the Statbel census: age, sex, marital status, household type, education, occupation (ISCO), industry (NACE), and crucially the commune (all 581 of them). The distributions match the 2021 Census across each of these axes. The banner above shows the median annual income by commune as it falls out of the personas; the familiar Belgian geography (the Brussels periphery, the Walloon-Brabant belt, the Flemish coast) emerges from grounding on official statistics rather than being imposed by hand.
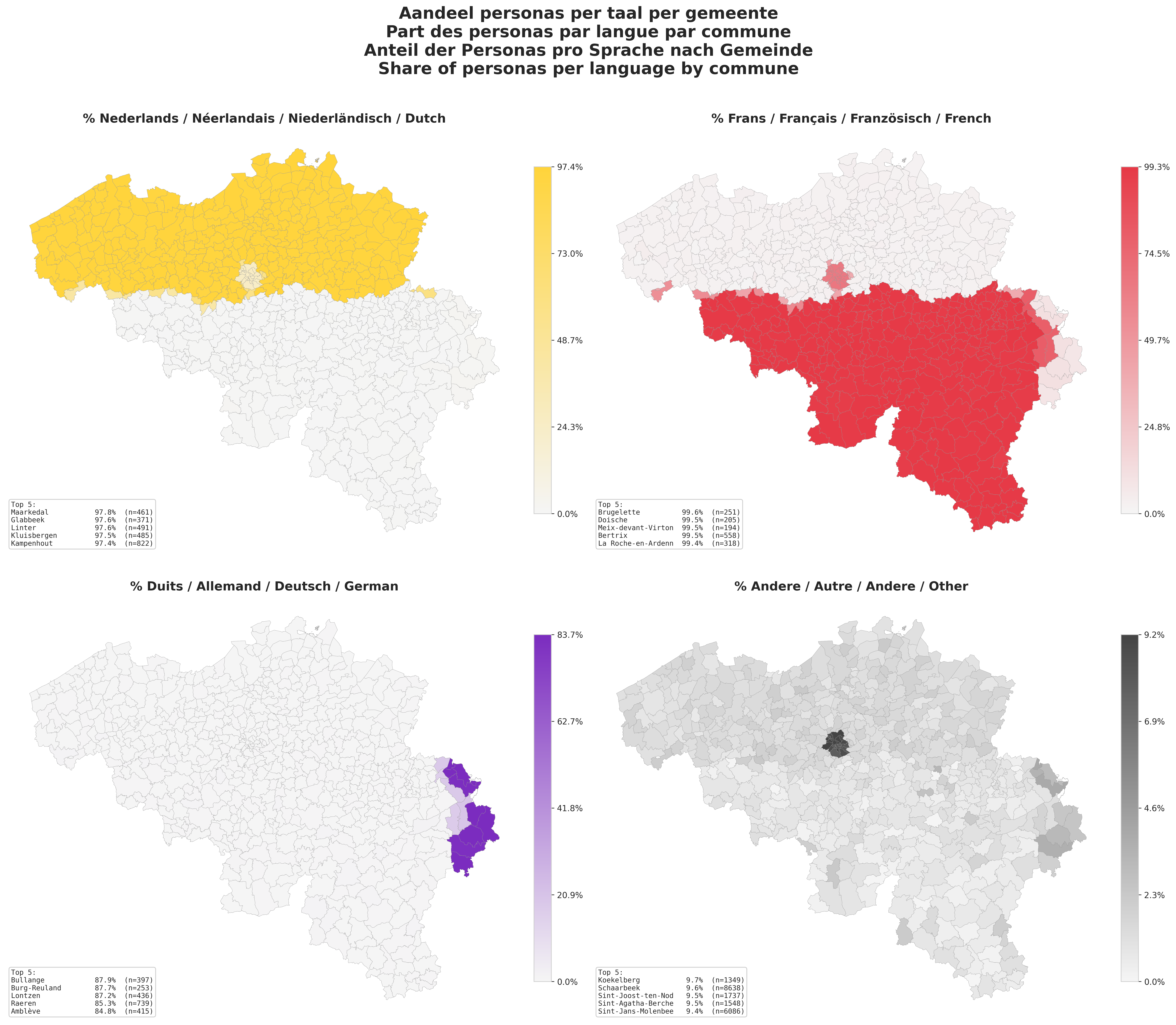
The language problem
If you know Belgium, you know language is the topic. The country is split into Dutch-, French- and German-speaking regions, with Brussels officially bilingual and a handful of facility communes around the edges. The 2021 Census, for historical political reasons, does not ask about language anymore, but we obviously cannot release a Belgian persona dataset without modeling it.
So we reconstructed the language distribution from commune-level geography and the official language areas defined in the Constitution. The end result roughly matches the commonly-cited split: ~58% Dutch, ~39% French, ~1% German, with the remainder being other home languages.
Fully multilingual personas
Every persona exists in all four languages: the same person, with the same job, hobbies, household and life story, written in Dutch, French, German and English. So for each of the 300k personas, you get four parallel versions, useful both for sovereign-AI training in any of the three national languages and for cross-lingual research.
If you've followed my earlier work on Dutch LMs, you'll know I think this kind of multilingual grounding matters for mid-resource languages. A Dutch-speaking persona "translated" from an English template often reads as Flemish in all the wrong ways: calques, off-register, the kind of text a Dutch reader clocks instantly as not-quite-right. Here the demographic anchor is shared but the writing is generated natively per language.
What's in the schema
23 fields per persona. The interesting ones:
- 6 persona fields: a general
persona, plusprofessional_persona,sports_persona,arts_persona,travel_persona,culinary_persona, so you can sample at the granularity you need. - Skills, hobbies and career goals as both free-text and JSON-encoded lists.
- Cultural background with ~16 heritage categories and 260k unique names drawn from the official first-name and family-name registries.
- Demographics: age, sex, marital status, household type, education level, ISCO occupation, NACE industry, commune, region.
What we deliberately don't include: individual names as standalone fields (to make memorisation/re-identification hard), the income itself (aside from the financial persona), religion, and anyone under 18.
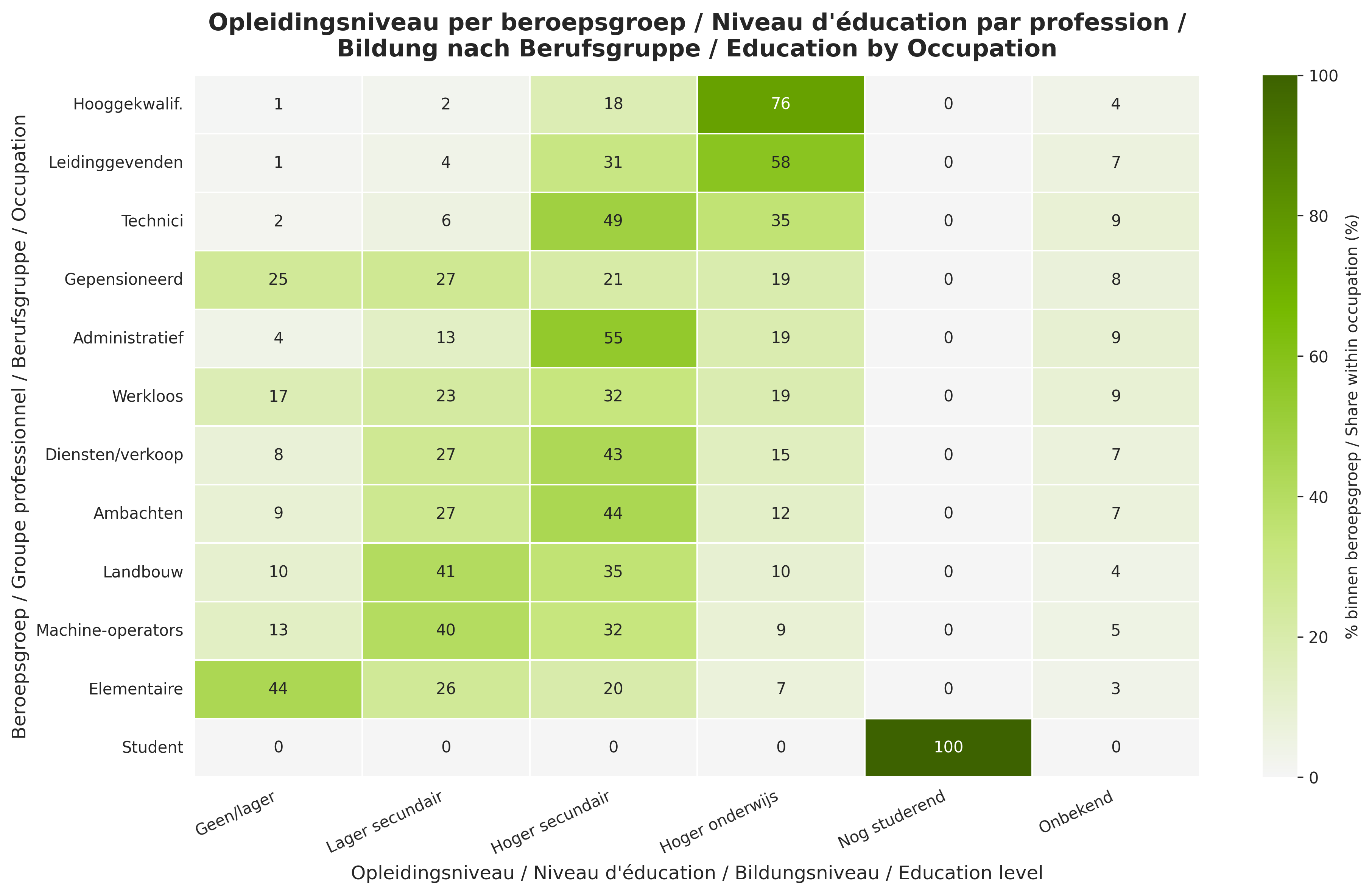
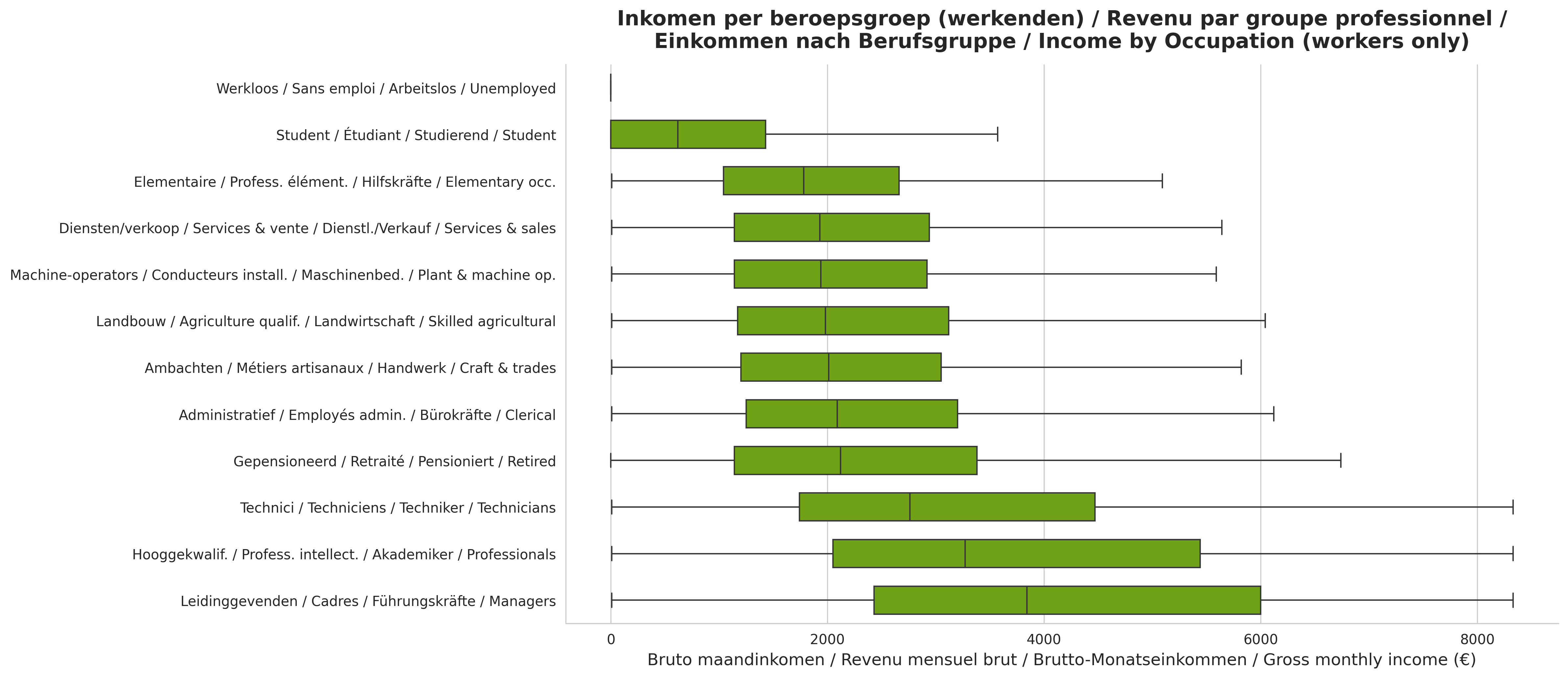
Use it
from datasets import load_dataset
ds_nl = load_dataset("nvidia/Nemotron-Personas-Belgium", split="nl_BE")
ds_fr = load_dataset("nvidia/Nemotron-Personas-Belgium", split="fr_BE")
ds_de = load_dataset("nvidia/Nemotron-Personas-Belgium", split="de_BE")
ds_en = load_dataset("nvidia/Nemotron-Personas-Belgium", split="en_BE")CC BY 4.0, 1.9B tokens total, ~4 GB in Parquet. Built with NeMo Data Designer on top of a Gemma base model.
Acknowledgements
This was joint work between Pleias, NVIDIA and KU Leuven. Co-authors: Pierre-Carl Langlais, Anastasia Stasenko, Yannick Detrois, Meriem Bendris, Benedetta Delfino, Shyamala Prayaga, Ashton Sharabiani, Bardiya Sadeghi, Will Jennings, Kiran Praveen, Maarten Van Segbroeck, Dane Corneil, and Yev Meyer.
If you build something interesting with it, I'd love to hear about it.