Watch the 13-minute video explainer here.
Almost a decade ago, it was incontrovertibly shown that NLP systems could process language as a sequence of sub-word units just as well as (and often better than) processing full words instead. With that, the field of sub-word tokenisation was born, tasked with splitting words into such sub-word units. Riding on the success of attention in LSTMs and later in transformers, the byte-pair encoding (BPE) tokeniser has become the default sub-word tokeniser: it is used in popular models such as LLaMA, the family of GPTs, Mistral etc... and requires no hand-crafted linguistic resources, like the models we train.
BPE
Based on the compression algorithm of the same name, BPE works by merging the smallest data unit (characters or bytes) into bigger and bigger units until it no longer can. Training starts by splitting a corpus into words and those words into characters. This set of characters is the alphabet, and is used to initialise the token vocabulary \(V\). The training algorithm then iteratively finds the most frequently occurring pair of adjacent tokens \((x,y)\), concatenates them into a new token \(xy\) everywhere, adds that to the vocabulary, and remembers this merge \((x,y) \to xy\) in a (ordered) list \(M\). This continues until the vocabulary reaches a pre-set size. That's how easy it is to train a BPE tokeniser \((V,M)\).
Then, to tokenise any new word, it is split into characters, and the
list of remembered merges \(M\) is
replayed in order, where any merge that is possible in the given word is
applied. Ideally, this segments a word into the most linguistically
meaningful units. Unfortunately, BPE has no notion of linguistics,
meaning it often merges characters that should definitely stay
separated. For example, the BPE tokeniser used in RoBERTa, which has
picked up on frequent patterns in the English language, is very quick to
merge e and s into one token es.
Compound words such as horseshoe, which should ideally be
segmented into two tokens horse/shoe, are predictably
botched by BPE:

Clearly, there is a need to supplement BPE's unsupervised training with linguistically informed data.
BPE-knockout
We present BPE-knockout, a post-processing step for existing BPE
tokenisers that eliminates problematic merges. Given a dataset that
shows the desirable segmentation for sufficiently many words -- in our
case, that's a segmentation into morphemes, the building blocks used by
the language itself to compose a word, as in the famous
dis/establish/ment/arian/ism -- we let BPE tokenise the
same words and compare the desirable segmentation with BPE's
segmentation. Since every merge removes exactly one separation between
two characters (by contracting the tokens those characters are part of),
the disappearance of a desirable segmentation boundary can be blamed on
exactly one merge. We count up how many times \(N(m)\) every merge \(m\in M\) is applied and how many times
\(B(m)\) it is blamed out of those.
Hence, we know which merges cause more harm than good
overall, namely when \(B(m)/N(m) \geq
\frac12\) (i.e. they remove a desirable boundary the majority of
the time they are applied) and we disable such merges
permanently.
Disabling a merge \((x,y)\to xy\) means that the token \(xy\) can never be formed again. That would in turn imply that every token formed using \(xy\), by merges like \((xy,z)\to xyz\) or \((z,xy)\to zxy\), would also never be formed again; we get a recursive cascade of disabled merges. To prevent such unintended consequences, we design a more surgical knockout procedure, where we only remove the token \(xy\) and its merge, but we keep merges that used \(xy\) by replacing it with its parents: the two-token merge \((xy,z)\to xyz\) becomes a three-token merge \((x,y,z)\to xyz\) and so on. Since BPE's vocabulary \(V\) and merges \(M\) are really just vertices and edges in a graph, knockout can be easily visualised in the \((V,M)\) graph that represents the tokeniser:
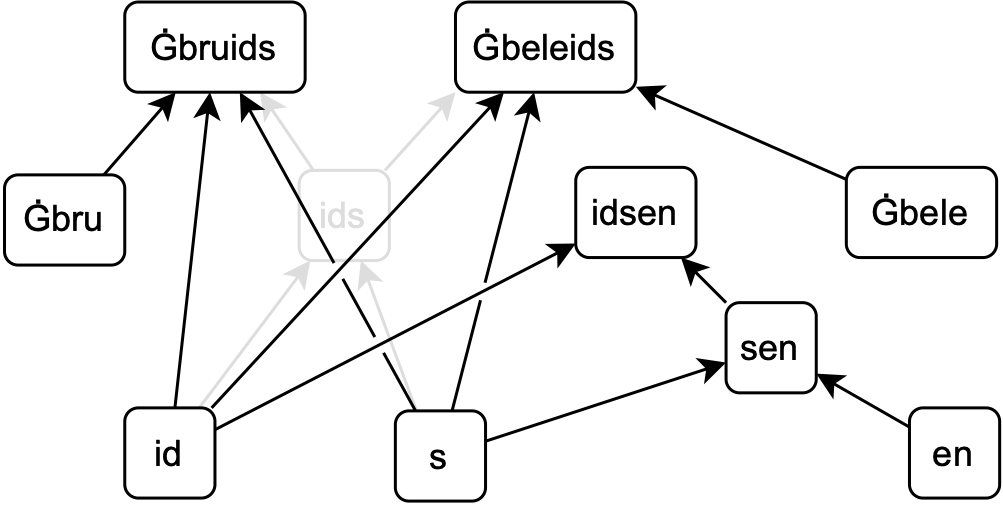
By knocking holes into the BPE merge graph informed by desirable segmentations, we effectively inject linguistic knowledge into the otherwise unsupervised BPE tokeniser, in such a way that it remembers it in future segmentations. This is in contrast to training BPE on a pre-segmented corpus, which still crosses desirable boundaries at inference time despite never having done so at training time.