Fair models — Why should we care?
Machine learning models are integrated in an ever-increasing amount of decision support systems. Banks use it to judge if an applicant can have a loan, predict if a pre-trial inmate is eligible for parole, set credit cards limits etc...
All these models are trained on data. This is often the data that companies and instances have at hand: things like historical records and customer data. Unfortunately, this kind of data is often not free of unfair patterns.
Let's take the credit card limit as an example: Apple released a credit card in the US with Goldman Sachs. Soon after, people started noticing vastly lower spending limits for women. Even for married couples with joined assets—like Apple co-founder Steve Wozniak—people reported 10x or 20x differences.
Sadly, not a lot of information about this specific incident is known. Nevertheless, this is not the only instance where people noticed discrepancies between different groups. ProPublica's article on bias against Blacks in COMPAS is another example. This case even sparked some debate about what the outcome of a 'fair' and 'unfair' model should be.
What is fairness?
In the case of COMPAS, the developers, Northpointe, replied that COMPAS is fair ... according to their metric: predictive parity. This difference in conclusion stems from different interpretations of fairness being encoded in different metrics, which obviously results in a wide array of metrics.
It would lead us too discussing all these metrics in this blog post. We selected two popular ones: demographic parity (DP) and equality of opportunity (EO). If you want to know more, check out the Fairness and Machine Learning book by Barocas et al. »
For demographic parity, we look at the difference (or ratio) for two groups in receiving a positive prediction. Since this metric this doesn't take the individual's capabilities into account—the number of positive predictions just has to be equal for both groups—this is often considered inadequate as a metric for fairness.
Equality of opportunity expresses these individual merits by including the true outcome in the metric. For example, this would mean including wether or not people actually committed other crimes for COMPAS.
Obtaining this 'true outcome' is quite difficult, however. In the case of COMPAS, people with a high risk are unlikely to be released and this affects the statistics that are later used to evaluate the risk prediction system. It is thus important to keep the context and social setting in mind when evaluating algorithms!
Learning with fairness
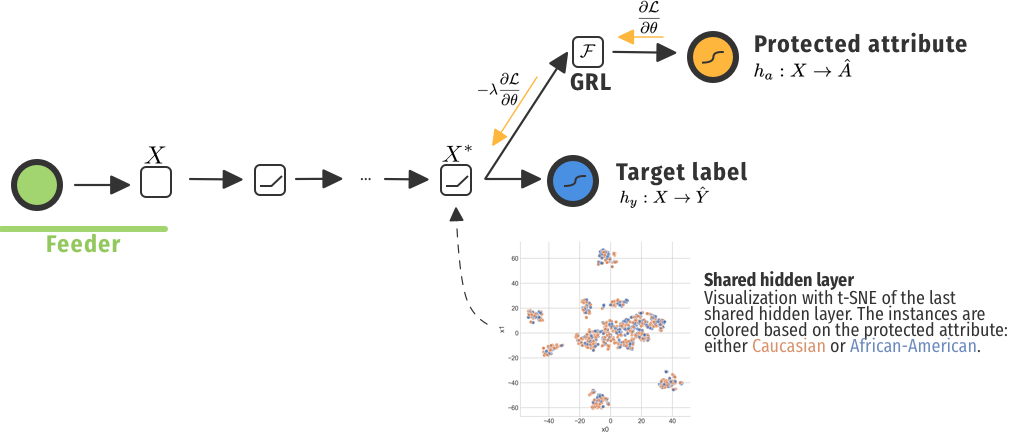
Fair models have been studied for a variety of learning algorithms, such as Naive Bayes classifiers or SVMs. Nowadays, the focus is also on neural networks where dedicated architectures have been proposed. We look at architectures with a Gradient Reversal Layer (GRL) introduced by Ganin et al.
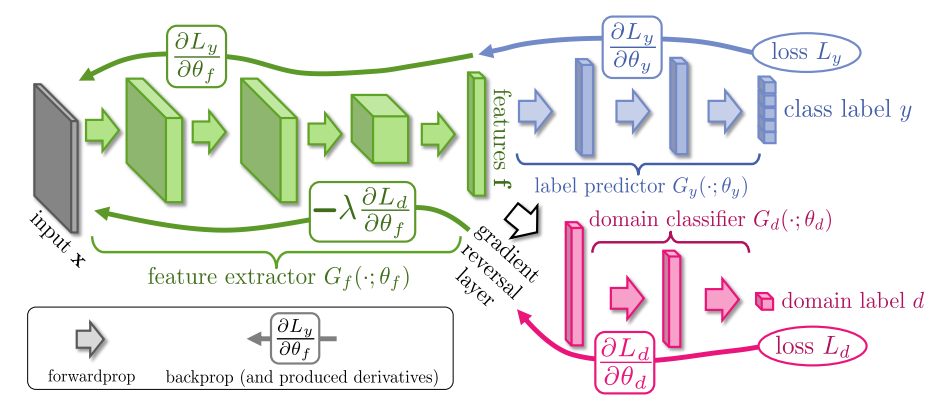
This GRL is a general approach to domain adaptation, which was used by Adel et al. and Raff et al. for fairness. In both cases, the network has to predict two outputs: the protected attribute and the target attribute. During backpropagation, the gradients are multiplied with -1 for the protected attribute, which should account to "being maximally invariant to the protected attribute". Is that the case?
How do they learn this? Or: are my representations fair?
Our premise is that that is not the case. At least not without some additional measures. In the paper we look at this more closely, but the gist is that flipping the gradients for the shared hidden layers still learns the protected attribute. After all, the best way to be wrong is to have the right answer and say the opposite.
As an illustrative example with COMPAS, we looked at the last hidden layer for a normal neural network trained on predicting recidivism. We visualized the activations with t-SNE. While we did not use the protected attribute Race as an input feature, it was still a bit present in the representations. In fact, with transfer learning, we suddenly had a classifier for this attribute with an Area Under the Curve (AUC) score of 0.71. That's is ... not something you want.
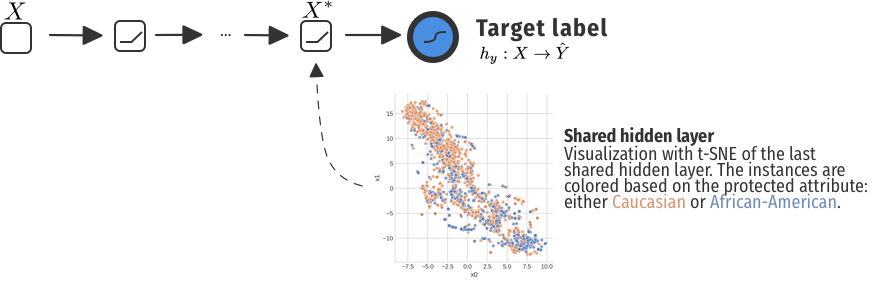
That was for a simple network to predict recidivism without taking the protected attribute Race into account, but also not actively mitigating any unfair behaviour. When including the a GRL, we get a totally different picture.
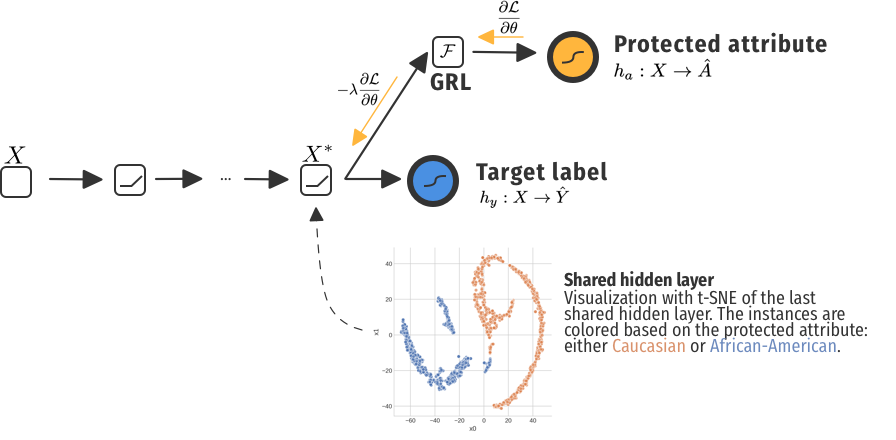
Oef. That's painful. In this example, we have a representation that seems separable... With a perceptron, we achieve an AUC of 0.92. That is way better than our naive model that didn't "mitigate" unfair behaviour. Is this really fairer, since these clearly biased representations are also used to make predictions on the risk of recidivism?
Can we do better?
The ethical adversaries framework
To mitigate these issues, we introduce an adversary. This adversary is based on research in model security, where adversaries introduce (training) examples that trick the model to misclassify that example, this is called an evasion attack. Optionally, they can also focus on attacking the training process specifically, which is computationally more expensive.
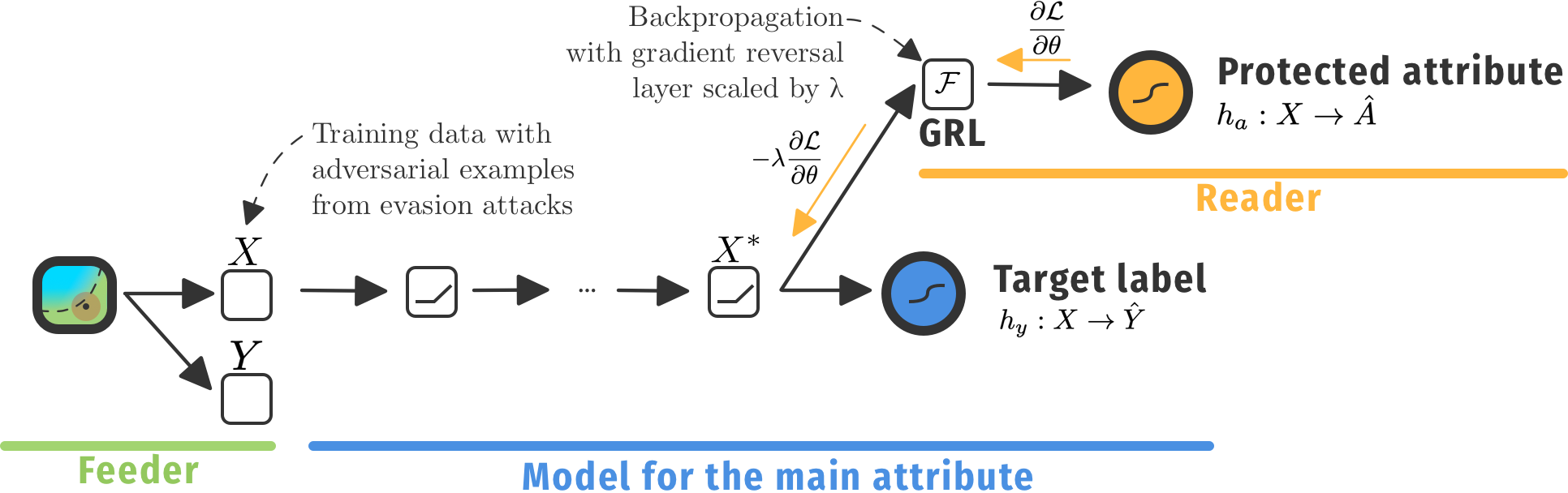
The entire framework is also decribed in more detail in our paper »
Results
Our architecture that joins the Reader and the Feeder, leverages utility- and fairness-focused methods in a better way than the modification of the model alone. By injecting noise with the adversarial Feeder, our framework successfully mitigated this unfair representation, as shown in the illustrative example on COMPAS.
Adversarial fraction
We also investigated how our framework can gradually improve fairness and utility, by only introducing a small amount of adversarial examples during each iteration. We observed that our framework can improve the utility for several iterations, up to 20-25% of original dataset size. After that, the performance goes down again. Interestingly, fairness also improves simultaneously.



What's next?
This is very much a work in progress. Some possible lines of future work are on the effects of the different hyperparameters and a pareto analysis of the trade-offs between utility and fairness.