In our ECML-PKKD '22 publication, we propose a more efficient way to create language models using counterfactual data augmentation (CDA). One of the drawbacks of existing methods was namely that it required pretraining a new model, which is pretty expensive. To tackle this, we use knowledge distillation.
Knowledge distillation of language models
Initally, knowledge distillation was presented by Bucilă et al. (2005) and a decade later by Hinton et al. (2015) as a method to combine the predictions from an ensemble of models and learn a single student model. Nowadays there is often only a single, bigger teacher model.
The predictions from this teacher model are used to train a new
student. This is a more informative training signal than the normal MLM
objective. As an example, just compare the predictions for this
sentence (sorry, I couldn't think of a better sentence). All the
predictions, up until milk is a milk, make a lot of sense.
With MLM, only the word that was originally in the sentence is
considered the correct one, even though multiple options are
correct.
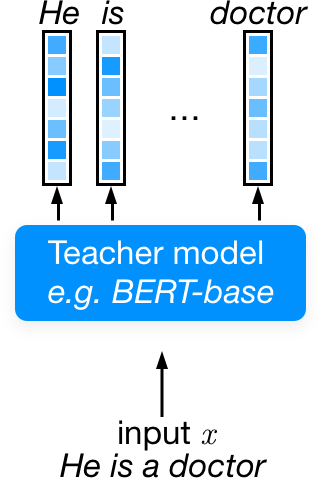
Now, given enough data this smooths out and the predictions are quite useful, but this requires a lot of training data. By using all other predictions, and even ones other positions than the mask token, there is a lot less data needed to get to an acceptable level of performance.
We still have to train the teacher model (with the traditional MLM), so that is not the main advantage of knowledge distillation. The student models we get are also smaller and still quite performant, so that is a big benefit. Smaller models need less storage and are easier (cheaper) to finetune and deploy.
In conclusion, knowledge distillation is an interesting method to create smaller language models. Because all the predicted probabilities are used a training signal for the student, this sets the stage to introduce fairness constraints as an alternative to CDA.
Fairness constraints
The predictions of the teacher model can be used to train a smaller model where we also introduce some fairness constraints. These constraints can in theory be anything; although our implementation only supports single-token substitutions. There are some lists of substitutions we could use, such as AugLy, but we focused on pronouns for simplicity and because it's a bit tricky to measure bias with the same lists of professions that we use to mitigate those biases.
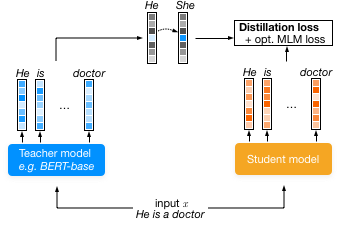
We tested this on BERT, an English model, and RobBERT, a Dutch model. Both seem to have less stereotypical predictions and the performance only took a minor hit, but is still on par with the distilled variants without fairness.
So this is a promising method to create fairer language models, although the reliance on substitution rules still makes it a bit brittle, but that's future work.