The recent success of pretrained language models on various tasks has prompted an increasing amount of research into exploring the gender bias present in these models. As pretrained language models are trained and finetuned on text corpora, bias can manifest in two ways: intrinsic bias, which is present in the pretrained model, and extrinsic bias, which exists in downstream models based on the pretrained model. Our EACL '23 paper aims to investigate the impact of intrinsic bias on extrinsic fairness and whether commonly used bias mitigation techniques are effective in resolving bias or merely masking it.
We developed a probe to uncover intrinsic bias and use it to evaluate the efficacy of various mitigation strategies. Our findings suggest that how intrinsic bias has been measured and the choice of bias mitigation strategies explored by some existing works have been suboptimal. Additionally, our probe helps to uncover whether some proposed mitigation strategies are concealing bias.
Bias mitigation strategies
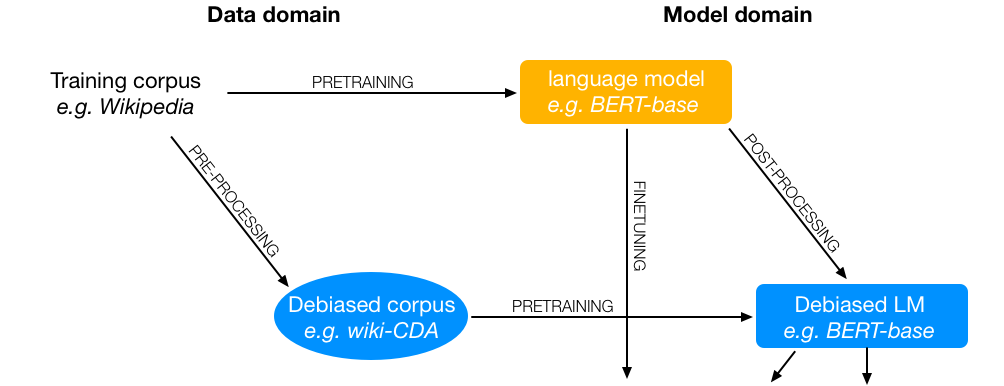
Intrinsic gender bias mitigation strategies modify the data, pre-training process, or outputs of the pretrained model. We've selected three popular methods: Counterfactual Data Augmentation (CDA), Context-debias, and Sent-debias - to reduce bias. These methods create debiased pretrained language models, which can then be fine-tuned for downstream tasks.
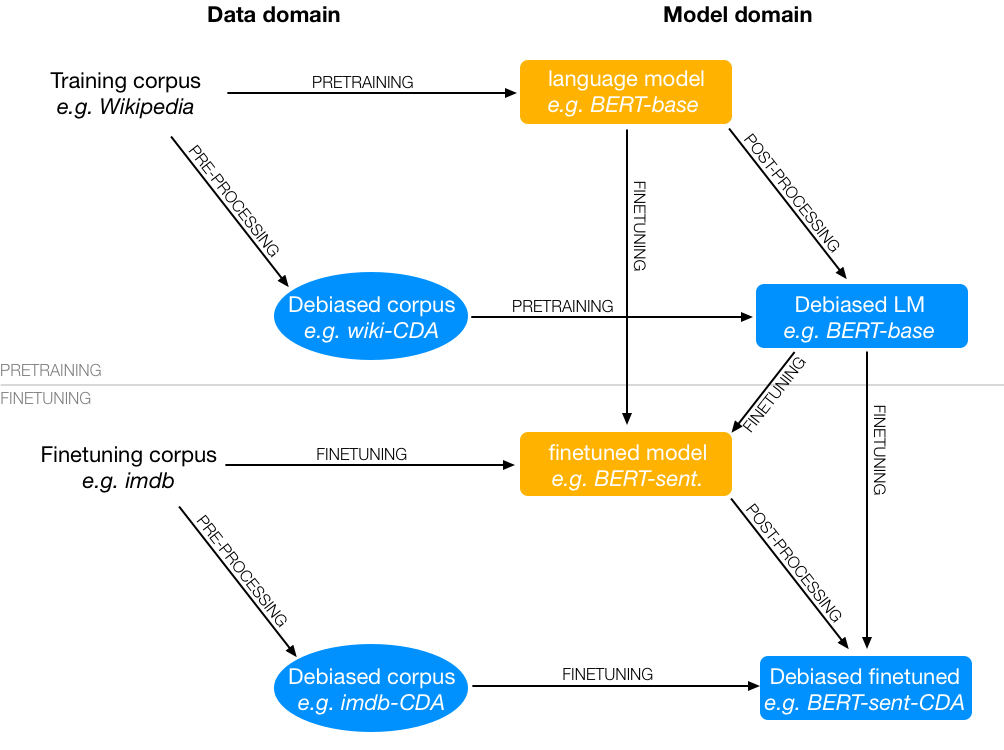
Methods like CDA change the training data, while others affect the model to create a debiased variant. In any case, this must be done as a pretraining step. Context-debias and Sent-debias are two popular mitigation methods that involve either a predefined set of attribute and target terms, or a gender subspace. All three methods enable the creation of a debiased pretrained language model, which can then be finetuned for a downstream task.
Similarly, we can also perform fairness mitigations on downsteam tasks. For example, Attribute scrubbing and Attribute swapping can be used to remove and replace biased words in a dataset, leading to presumably fairer downstream task results.
Probing for gender bias
We designed a probe to measure the amount of gender information retained in the embeddings of language models after applying bias mitigation techniques. This involved identifying two sets of attribute terms that define females and males respectively, two sets of stereotype terms associated with gender, and extracting word embeddings from a text corpus. We then trained a classifier on those embeddings to predict gender, which should work for the first set of terms, but not of stereotypical terms.
Results
Our results showed that intrinsic bias measures respond differently to bias mitigation techniques, and that some intrinsic bias techniques and metrics can actually hide bias instead of resolving it. We also found that intrinsic mitigation techniques do not show a significant improvement on fairness in downstream tasks, but downstream data processing and a combination of intrinsic and downstream data intervention can have a positive effect on downstream fairness.
In short, we made the following observations:
- Intrinsic bias measures showed contradicting results when subjected to different mitigation techniques
- Some mitigation techniques can conceal gender information
- Intrinsic mitigation techniques do not necessarily show a significant improvement on fairness in downstream tasks
- Combining intrinsic and downstream data intervention produces the best extrinsic fairness results
Conclusion
We have developed a probe to investigate intrinsic bias in two language models, BERT-large and ALBERT-large. Through our research, we found that intrinsic bias metrics and mitigation techniques can be sensitive to certain intrinsic bias mitigation techniques, and can even conceal bias instead of resolving it. We recommend that intrinsic bias mitigation should be combined with other fairness interventions for better results.