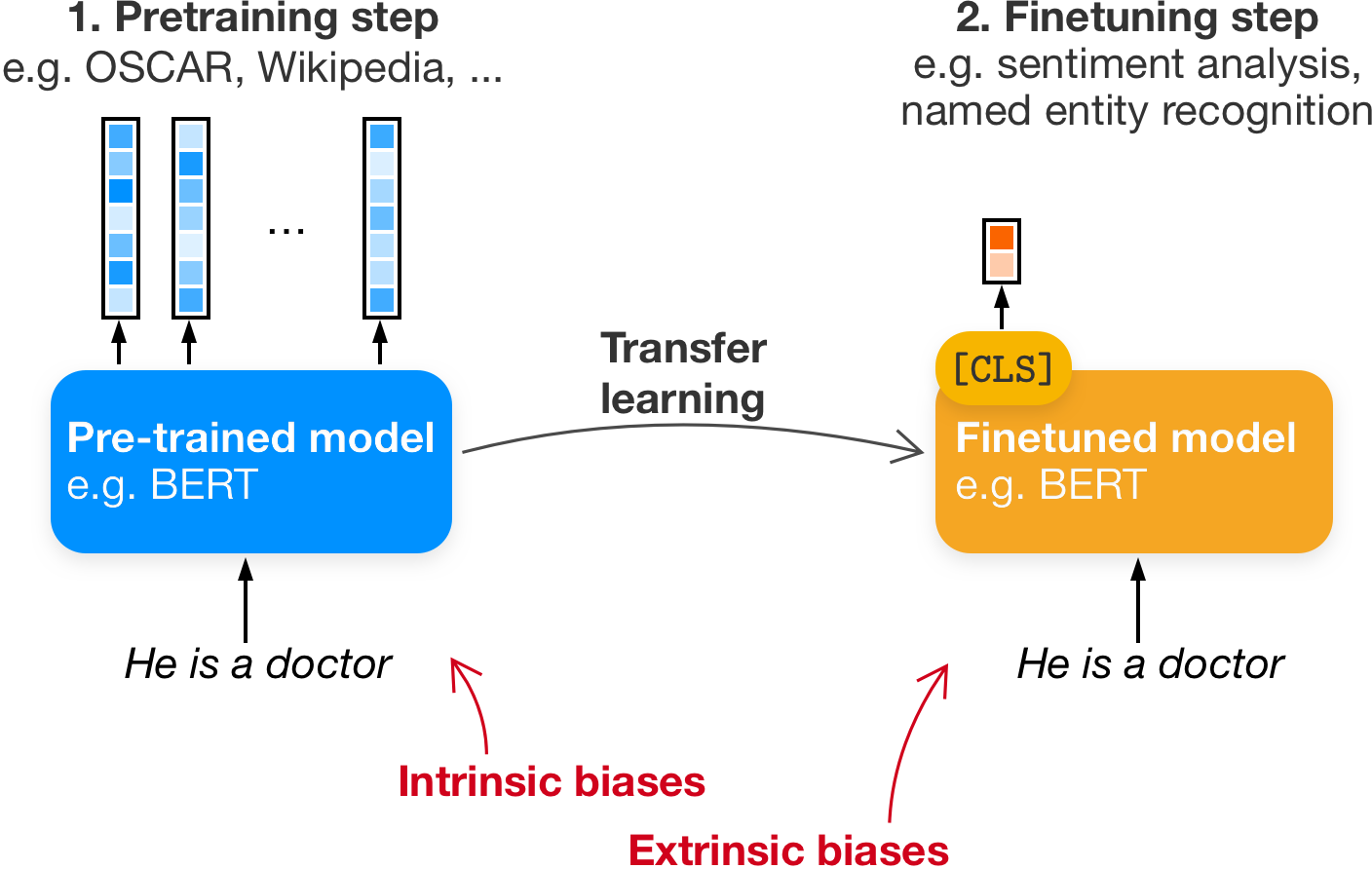
Fairness metrics for language models
When talking about fairness in language models, we distinguish between fairness or bias in the language resource itself (called intrinsic bias) or in a downstream tasks, like finetuning on sentiment analysis (called extrinsic bias). Our paper mostly focusses on the intrinsic bias measures, since the extrinsic bias really depends on the task and on the domain. Nevertheless, the assumption is usually that intrinsic measures serve as a predictor—or at least as an indicator—of bias in downstream tasks. Otherwise, why would we measure that?
Intrinsic measures
Our survey started when we noticed that there exist many different metrics to evaluate bias in language models, like BERT. This makes it difficult to compare results and how effective fairness interventions are, so we decided to get started on a survey. For a complete list, we refer to our survey, but for a more intuitive coarse overview: keep reading.
Most intrinsic metrics are based on some stereotypical association, like "He is a doctor" or "She is a nurse.". There are tested using templates with one or more slots. So can the previous example be generalized to "[MASK] is a [profession].". We can then fill in the profession slot and let BERT do the rest for the masked slot. This also relies on seed words, so that is already questionable and has been shown to contain biases.
Some measures, like SEAT and its variants, also rely on embeddings. This is another tricky thing to get right, since there are a few ways to obtain a contextualized embedding of a word.
Compatibility of measures
We did multiple correlation analyses to test the compatibilities between embeddings, templates and metrics themselves. By either varying the set of seed words or the language model, we obtained some slightly different results that we could use to calculate a correlation score, the Pearson Coefficient.
Compatibility of templates
We tested how different template are correlated with two embedding strategies and saw that some template correlate with each other, but most don't. Using mean-pooled embeddings, we at least got a bit more consistent results and we can clearly identify the two unbleached templates (T10 and T11).
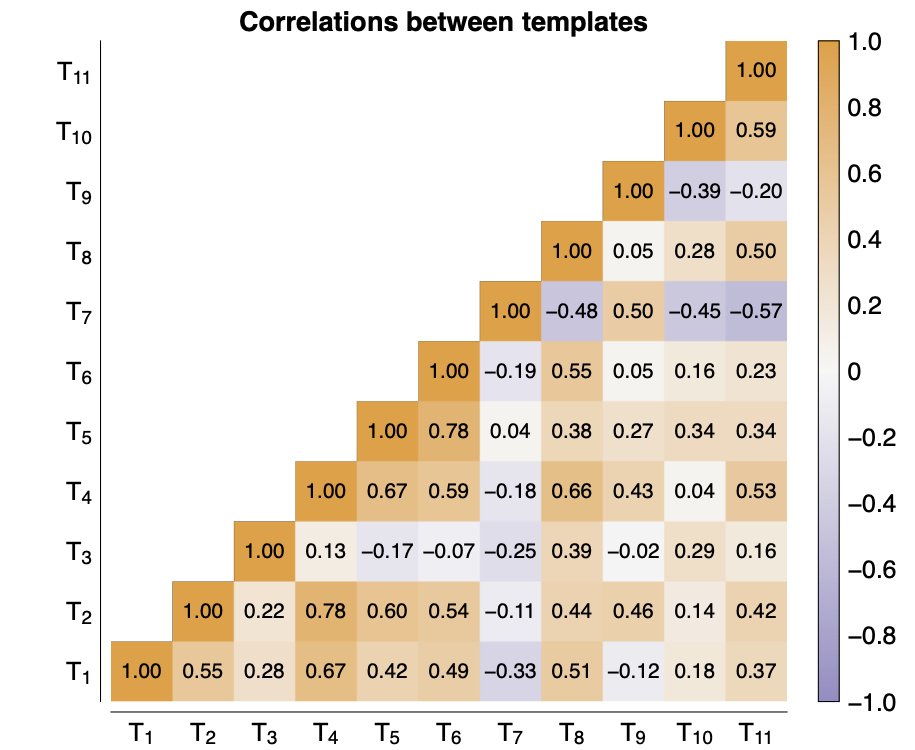
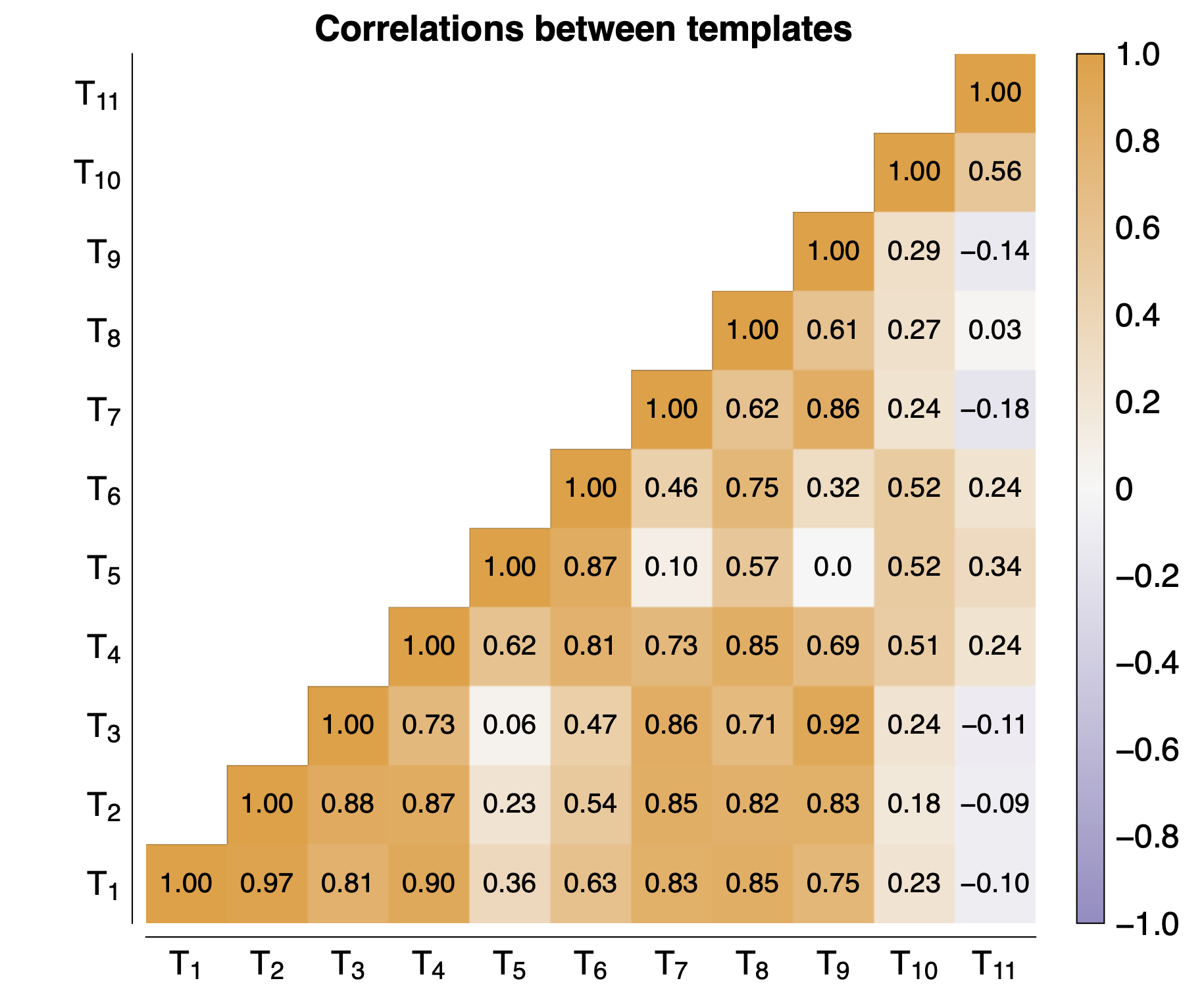
Compatibility of embeddings
The results of our two template experiments already showed significant differences between both embedding strategies, so we compared 6 embedding strategies. These results are, well, also not ideal. We see that both [CLS]-type embeddings are not really correlated with other types. and worse, they are not even correlated with each other... The other embedding methods are a lot more correlated, so that might mean that metrics using those embeddings are also comparable. But for example SEAT and a variant by Lauscher et al. (2021) are not really comparable because of this, even though both are based on WEAT.
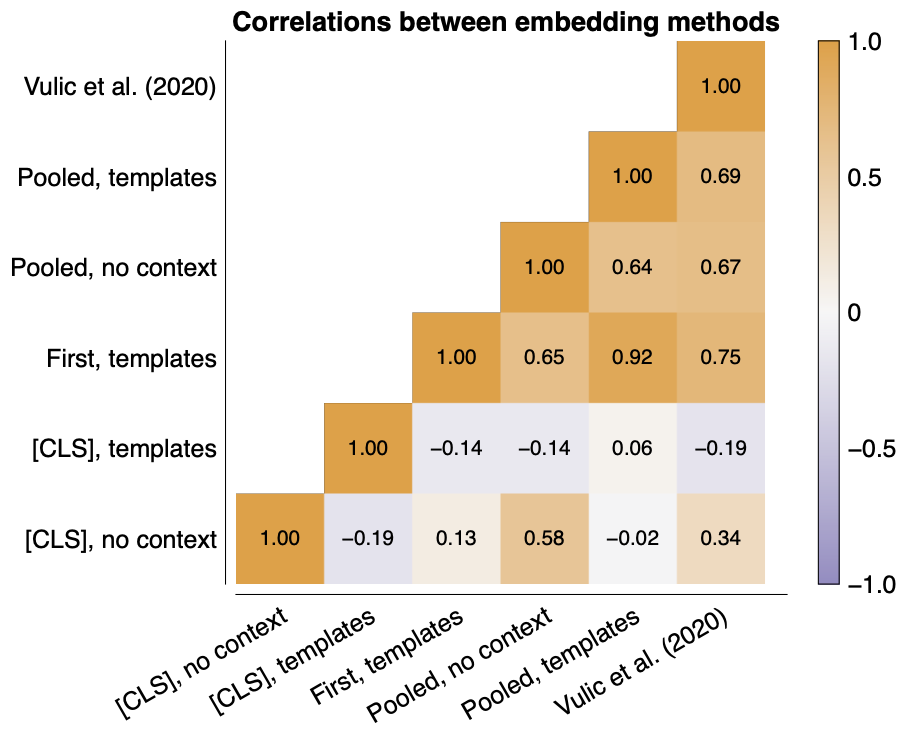
Compatibility of metrics
Finally, we also test different intrinsic measures and we see that these differences in templates and in embeddings really affect the final metrics as well. There is also an extrinsic bias measure in the following figure, BiasInBios, which uses personal biographies to test for stereotyping. Here, higher scores are better instead of worse, so we have a negative correlation with some metrics. However, only -0.8 for the best-correlating method is not great...
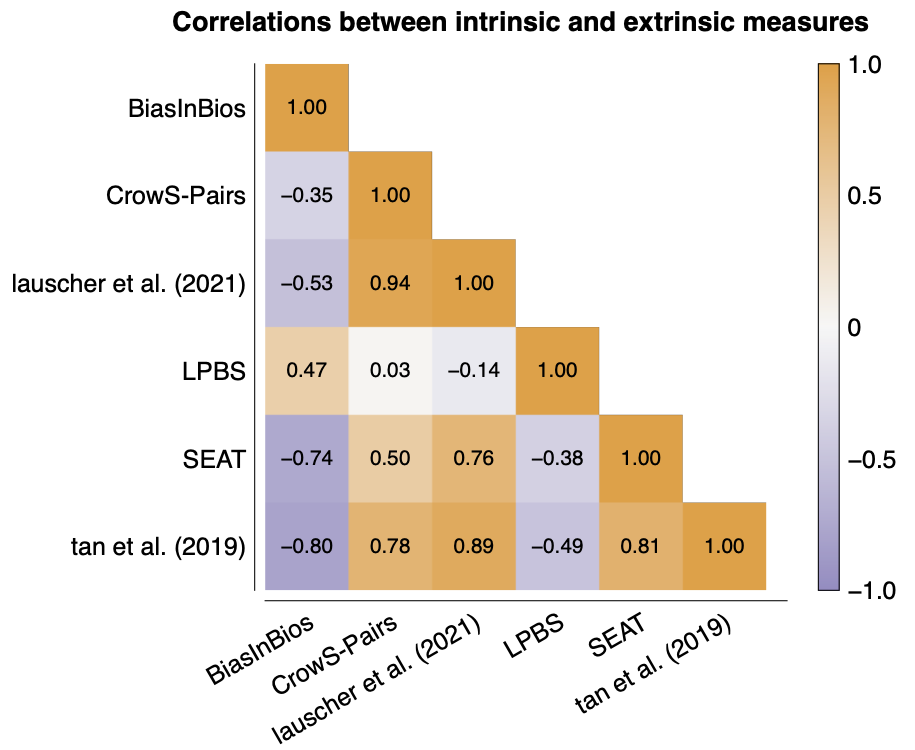
Conclusion and recommendations
So we observed that many aspects of fairness metrics don't correlate with each other. More importantly, we also observed that intrinsic measures don't correlate very well with BiasInBios, an extrinsic measure of fairness. That leaves us with some questions (yay, future work!), but that also highlights that we should definitely try to perform extrinsic fairness analyses. So our recommendation is to focus on extrinsic evaluations, but if you had to pick an intrinsic measure, you can at least eliminate one source of variance by selecting a measure without embeddings.