In this blog post, we discuss the challenges of creating a Dutch language model and introduce a method to address these issues. While we were able to create a Dutch version, called RobBERT, by pre-training from scratch, this approach is not always feasible due to limited compute budget (mid-resource setting) or insufficient data (low-resource setting). English, on the other hand, has a wide range of high-quality models available. These English models are trained for longer durations and have more parameters, which is illustrated by the absence of a large Dutch model until now.
We propose a method that leverages the existing work on English models. By utilizing the knowledge and techniques developed for English language models, we can overcome the limitations of creating large Dutch models. In the following sections, we delve into the details of language models, introduce the Tik-to-Tok method, present its benefits, showcase real-world examples, and discuss the results. In conclusion, Tik-to-Tok offers a promising approach for language translation, and we encourage readers to explore the research paper for further insights.
Language models
Language models, particularly masked language models, are deep learning models that are trained on large amounts of text data to understand and generate human language. They utilize a technique called masking, where certain words in a sentence are randomly replaced with a special token. The model's objective is to predict the original masked words based on the surrounding context. By doing so, masked language models learn to capture the statistical properties of language, including word relationships, contextual meanings, and syntactic structures. This enables them to generate coherent and contextually accurate text. These models have significantly advanced natural language processing tasks, such as text classification, named entity recognition, and language generation.
In this blog post, we’re gonna focus on masked language models (MLMs), but the general idea and architecture are similar for autoregressive language models like GPT.
Language models consist of different components: a tokenizer, an embeddings matrix, a stack of attention layers and finally some task-specific heads. The training of an MLM is done with a masked language modelling head, so to predict the correct tokens for masked positions.
the components we’re focusing on are at the beginning: the tokenizer and the embeddings matrix. These are what makes a language model unique to a language, and what makes it challenging to transfer models (or to distill them) to different architectures: the tokenizer is usually different.
The most common tokenizer is BPE, which uses subwords to translate sentences into sequences of token ids. For example, the sentence “No, I am not a giraffe” gets transformed into the following sequence with the GPT-4 tokenizer:
['No', ',', 'I', 'am', 'not', 'a', 'gir', 'affe', '.']Sidenote, there is also some logic to handle the spaces. One approach
is to add a space in front of the token (which we do and indicate with
_), another one would be to show the merges (as BERT does
with ##). This gives us this sequence.
['No', ',', '_I', '_am', '_not', '_a', '_gir', 'affe', '.']That then gets converted to a sequence of ids:
[2822, 11, 358, 1097, 539, 264, 41389, 38880, 13]And every single one of these id’s corresponds with an embedding, which is just a sequence of numbers again.

These embeddings are important. They are not yet contextualized (which is what the later layers do), but they give a meaning to each token. This matrix is also huge, it is 30% of all weights in base RobBERT. The other weights are spread over all attention layers (12 heads x 12 layers) and some other fully connected layers. So in total, this weight matrix is an important piece of every language model, doesn’t matter if it’s an MLM or transformer or autoregressive language model.
The sad thing is that this matrix is tied to the tokenizer. Which
means that we have a tokenizer that is not great (like we evaluated in
our RobBERT paper) and not a lot of words have a unique token (like the
tokens _gir + affe), we lose a lot of our
weights space to storing redundant embeddings, giraffe could have been
one token with one embedding after all.
This is the problem we encounter when we want to transfer a language model from one language to another.
The tokens do not match up and common words in one language always get cut up into smaller subwords. That’s not ideal, since it introduces lot’s of dead weights and we use way more tokens than needed, with shorter possible sequence lengths and slower inference as a consequence. If we want to reuse a language model, this is unavoidable. Or is it?
Introducing Tik-to-Tok
The idea of our Tik-to-Tok method is pretty simple. A token like
giraf (in Dutch) should have the same embedding as the
token giraffe (in English). Although this example is
already a bit challenging—since it spans multiple tokens in a real
tokenizer—the idea also holds for tokens like Ik
(I in English).
For any words in a parallel corpus that map to tokens one-to-one, this is quite easy to do. We just take that mapping. For other tokens, we have to be a bit smarter.
We use our mapping of whole words to create a bilingual FastText
embeddings. All the tokens in both languages get an embedding in a joint
embedding space and we can simply query what the English
affe from our giraffe example should be close to. We then
pick the three closest tokens in the target language and that’s
basically it: we have an embedding for our new token.
Results & conclusion
This token translation is theoretically pretty simple and our experiments show that it works exceptionally well for two use-cases:
- For low-resource languages (like Frisian) it is often the only way to create a model. Our MLM model was trained with only 35 MB of data, but still was successful at the MLM task.
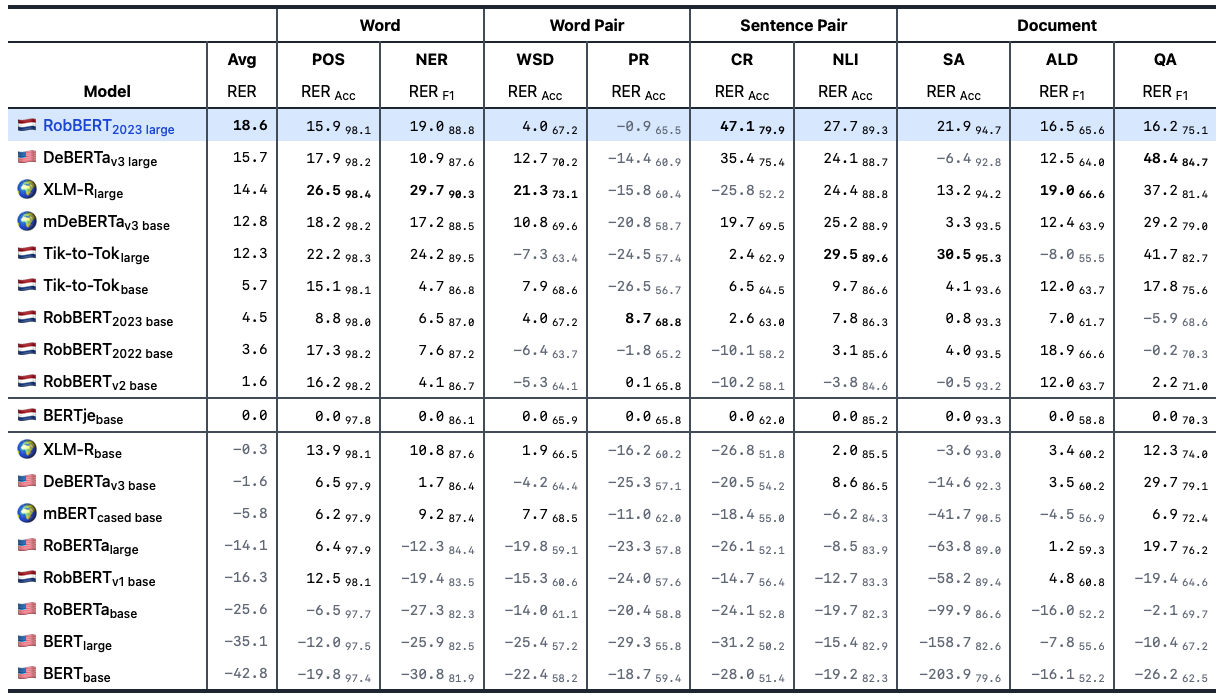
- For mid-resource languages (like Dutch), it can create state-of-the-art models based on the efforts done for English or other high-resource languages. We showed this by creating a new model, called RobBERT-2023, that beat all existing Dutch models.
Furthermore, because the method basically allows to initialize a language model with a different tokenizer, it could also pave the way for better domain-adapted language models. We haven’t tried this yet, but we are happy to help out if you have a use-case!