This is a blog post about the corresponding paper (pdf). In this post, you'll learn the following things:
- The state of emoji and emoticon support in different datasets and models.
- How to to extend BERT to leverage emoji and their semantics.
- How conversational models can be improved by emoji support.
Emoji are badly supported
Whether or not emoji are used depends on the context of a text or conversation, with more formal settings generally being less tolerating. So is the popular aligned corpus Europarl naturally devoid of emoji. Technical limitations, like no Unicode support, also limit its use. This in turn affects commonly used corpora, tokenizers, and pre-trained networks.
Take for example the Ubuntu Dialog Corpus, a commonly used corpus for
multi-turn systems. This dataset was collected from an IRC room casually
discussing the operating system Ubuntu. IRC nodes usually support the
ASCII text encoding, so there's no support for graphical emoji. However,
in the 7,189,051 utterances, there are only 9946 happy emoticons (i.e.
:-) and the cruelly denosed :) version) and
2125 sad emoticons.

Word embeddings are also handling emoji poorly: Word2vec with the commonly used pre-trained Google News vectors doesn't support the graphical emoji at all and vectors for textual emoticons are inconsistent. As another example with contextualized word embeddings, there are also no emoji or textual emoticons in the vocabulary list of BERT by default and support for emoji is only recently added to the tokenizer. The same is true for GPT-2. As all downstream systems, ranging from fallacy detection to multilingual résumé parsing, rely on the completeness of these embeddings, this lack of emoji support can affect the performance of some of these systems.
Conversational artificial intelligence
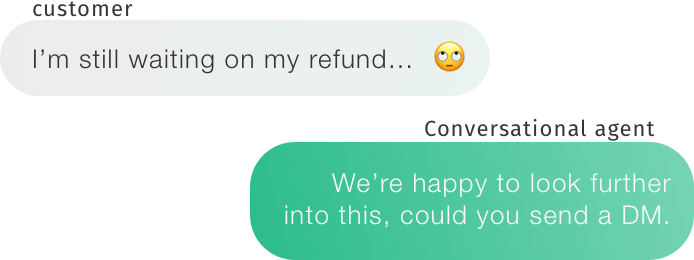
Emoji are often used in casual settings, like on social media or in casual conversations. In conversations---as opposed to relatively context-free social media posts---an emoji alone can be an utterance by itself. And with a direct impact for some applications, like customer support, we focus on conversational datasets. We hope the conversational community has the most direct benefit from these emoji-enabled models. Of course, the conclusions we'll draw don't have to be limited to this field.
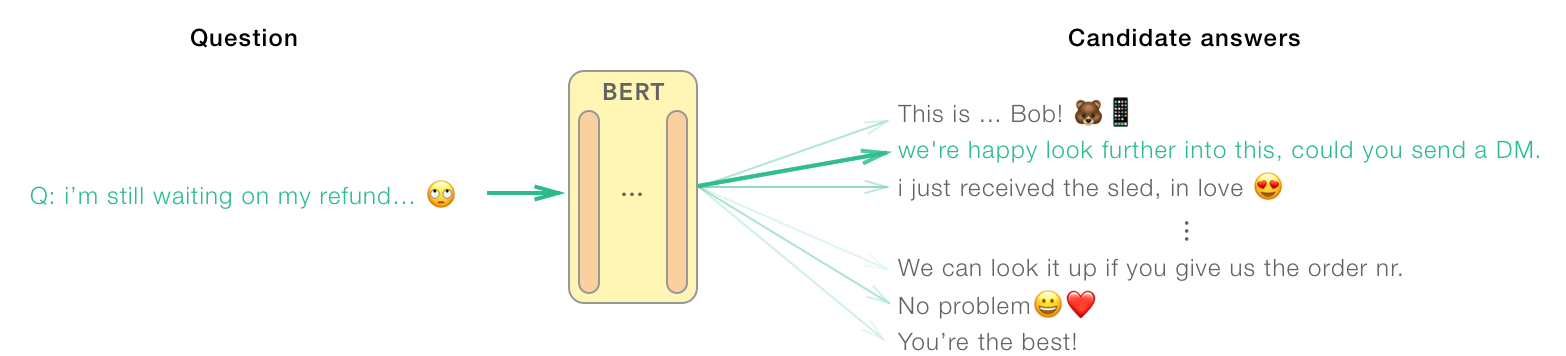
In this case, we'll format our problem as a response selection problem. During training, the model has to select the right response with one randomly sampled negative candidate. The stakes are higher during evaluation, where it has to choose between 99 negative candidates and only 1 positive.
This is a more restricted form of conversational AI, as opposed to generative models. However, it's still popular since it's easier to evaluate and responses are naturally limited to a whitelisted set. This way, companies offering chat bots don't get surprised by racist or inappropriate quotes from their bots, for example.
How to incorporate emoji in BERT
We used BERT-base-multilingual-cased as the baseline,
where we finetuned a specialised head for next sentence prediction. We
then continued training of the embeddings matrix, which was extended
with the tokens for every emoji from the Unicode Description.
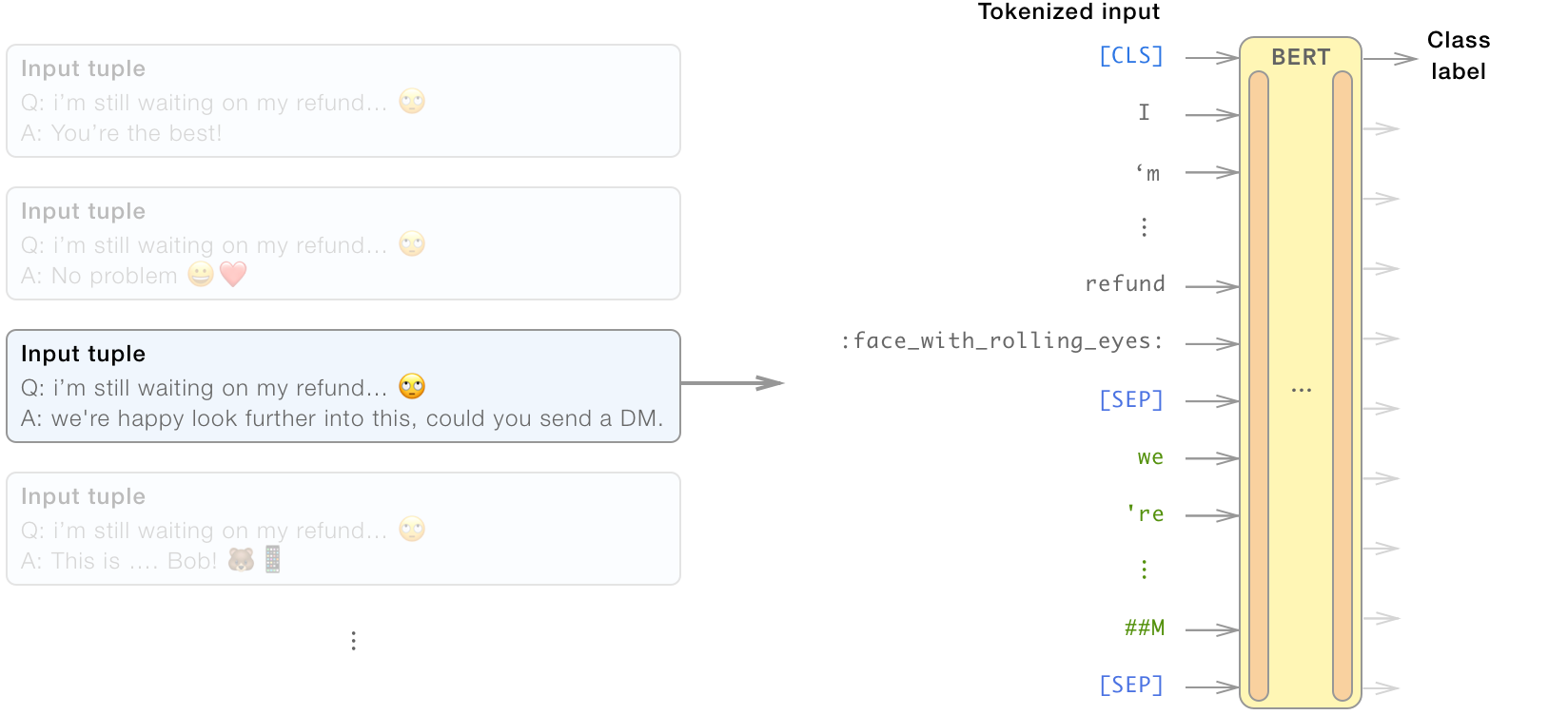
To get the emoji correctly in the BERT model, the tokenizer was also
modified a bit. Firstly, graphical emoji were replaced by a unique
description (i.e. :face_with_rolling_eyes:) to also support
custom emoji. Secondly, we added these descriptions explicitly to the
tokenizer.
The model with extended embeddings matrix and modified token-set was then also finetuned with a specialised head, in the same way as the baseline.
Results
Both the baseline and our model were evaluated on a held-out test set, where our model achieved a 1-out-of-100 accuracy of 17.8%, compared to 12.7% for the baseline model.
