We are excited to introduce tweety-7b-dutch a new Dutch
language model with a Dutch tokenizer. This model is created with our trans-tokenization method, setting it
apart from other Dutch models that are finetuned versions of English or
multilingual systems. Check out that blog
post for more details on the method.

The model
Tokenizer
Tweety-7B-Dutch uses a Dutch tokenizer, more specifically the yhavinga/gpt-neo-1.3B-dutch tokenizer, which is created on a Dutch corpus and has 50k tokens matching Dutch words or subwords. This specialized tokenizer offers an improvement in efficiency and quality for several reasons. Primarily, it matches more Dutch subwords, enabling each token to encapsulate a richer array of linguistic information. This also results in approximately 33% fewer tokens needed to process the same amount of text compared to models using more generic tokenizers. This reduction not only speeds up processing but also lowers computational costs significantly. Furthermore, the quality of language understanding and generation is enhanced, as the model deals with tokens that are intrinsically more meaningful and representative for Dutch.
Pre-training data
Tweety-7B-Dutch was pre-trained using yhavinga/mc4_nl_cleaned, a variant of the multilingual C4 dataset specifically cleaned and filtered for Dutch. This dataset is composed of high-quality and unfortunately also low-quality web-scraped content that has been filtered to remove most low-quality and irrelevant material.
The model was trained on a 8.5 billion tokens with a large context window of 8196 tokens, which means that Tweety-7B-Dutch can maintain context over longer passages of text, an essential feature for tasks involving understanding and generating coherent and contextually appropriate language outputs.
Model Versions
Tweety-7B-Dutch has a base version and an instruction-tuned chat version:
- base: This version is the foundational model that has been trained purely on the Dutch text corpus without any specific tuning for particular tasks.
- chat: Building upon the base model, this variant has been fine-tuned with a chat template, which tailors it more towards conversational AI and similar interactive applications. This tuning is designed to enhance the model's ability to understand and generate responses based on instructions or queries.
Performance
Perplexity
Tweety-7B-Dutch has achieved a perplexity of 7.7 on the held-out set
of the mC4 corpus, demonstrating strong performance in language modeling
tasks. This is lower than multilingual models, such as Mistral, although
this number cannot be compared directly since the tokenizers are
different. The perplexity of _gir + af is usually a bit
lower, averaged per token, than the perplexity of _giraf.
So to correct for that, we have to adjust
for the encoded length. This gives us an equivalent perplexity in
Mistral's tokenizer of 5.75. Not too bad and a lot lower than the 7.1 of
Mistral-7B-v0.1.
Zero-shot performance and few-shot performance
In addition to its zero-shot capabilities, we evaluate our model on the Dutch benchmark SQuAD-NL in the Dutch evaluation harness. We are still working on a more comprehensive evaluation, but initial results look promising.
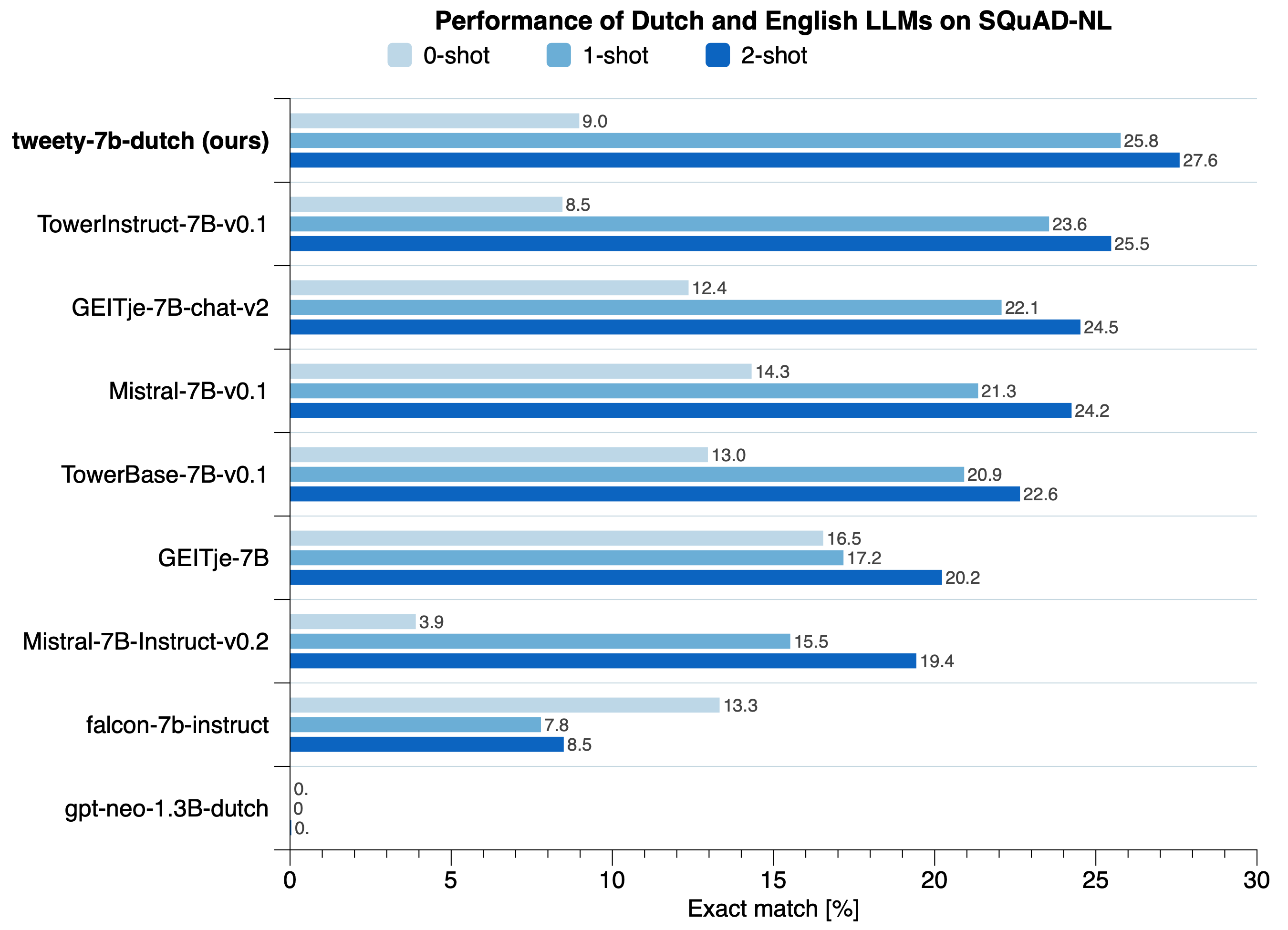
Related models
Tweety-7b-dutch is part of a series of trans-tokenized LLMs:
These models are created using the same approach. Since they are true low-resource languages there is simply no way to create a model for such languages otherwise. We can also swap the native head and the trans-tokenized head for some cross-lingual capabilities, such as zero-shot machine translation. For more details on this, check out the paper.



And we are also working on tweety-7b-italian-v24a