In part 1, I explained how we created a new tokenizer for RobBERT and how we prepared the data. These were the first steps to update our language model to 2022. Since that blogpost, we ran a training script for some time and we now have a model that we're quite proud of. Let's take a look!
Training
To pretrain the first versions of RobBERT, we used Meta's FairSeq library. This worked pretty well, especially because, back then, the HuggingFace library was not really so popular and we would have needed to implement the pretraining from scratch. So we trained in FairSeq and later converted the model to HuggingFace. There even was a script to do this, although we had to add an extra translation step for the tokens.
However, we had some occasional issues with our converted model. For instance, our model worked perfectly well for some time, but when the HuggingFace library moved to a faster implementation of the tokenizers, our model broke. It wasn't a big issue and we managed to fix it, but, in hindsight, those translations cost us a lot of time. So now we wanted to train with the HuggingFace library.
We used a training script that uses the HuggingFace models combined with PyTorch Lightning. This worked pretty well. The benefit of this library is that we get checkpointing, distributed training, data loading, etc. for free. We definitely needed the checkpoints, since our process got terminated a few times, as you can see in the validation chart.
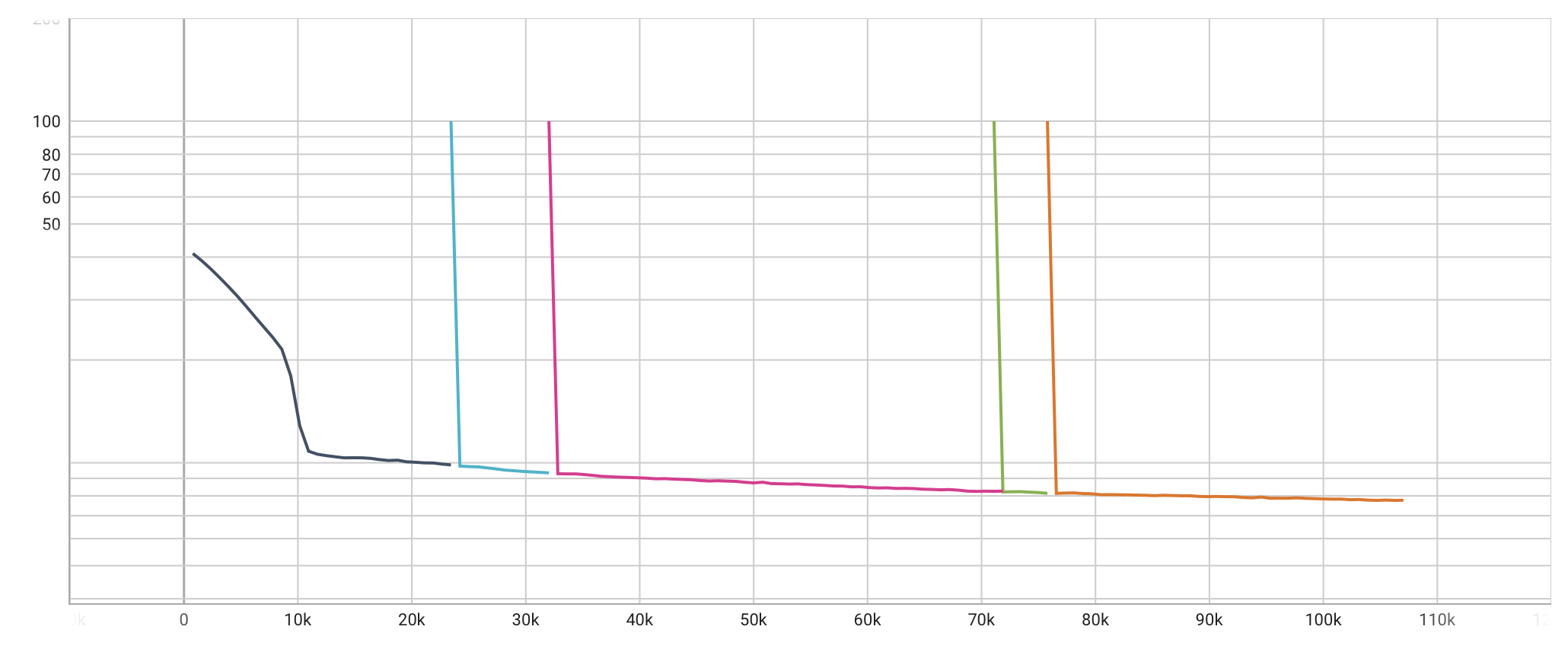
The interesting thing is that our model is now still getting lower and lower validation scores, so no reason to stop just yet. So we are still letting the training run, but we've been spending a lot of compute and we don't know yet if our model is any good.
Can RobBERT-2022 replace the original?
One of the first requirements is that any new model that we release must be at least as "good" as the old RobBERT model. Otherwise it is just confusing to have a new model that performs worse and which we would discourage people to use. This was actually the case when we were first evaluating a very early checkpoint of the model and we were hoping to catch a conference deadline. The model performed worse that RobBERT on the old benchmark tasks and on new tasks, so it made no sense to submit this model.
Luckily, the training continued and our new model does perform well on these benchmarks. We'll do a detailed writeup (or a paper directly) on these evaluations, but the gist is that most benchmark scores were pretty good and surpassed RobBERT.
Aside from getting high benchmark scores, the embeddings also have to be suitable as a replacement for RobBERT. People have been building applications with the embeddings directly, without finetuning, so if we now mess those up, those applications break as well.
Although it is a bit more difficult to analyze those embeddings directly, we can visualize them and see if there are any big differences in quality. I would hope to see the same kinds of clusters in both embeddings, which is indeed the case, as you can see in the following chart.
Since the training did not constrain the model to stay close to the original embeddings, there is some drift. Most clusters are present in both models, but they are mirrored in our visualization. This mirroring is mostly an artifact of the t-SNE dimensionality reduction, but it does show that the embeddings shifted enough to affect the t-SNE visualization.
Does RobBERT-2022 model language shifts?
Our previous model is from 2019, so over the last 3 years, the language has shifted a bit. I already discussed how we tested if the model is better or at least as good on old tasks, but how about new ones?
We've chosen two tasks about the COVID-19 pandemic, as this is one of the most telling events that happened since 2019 and many people created new datasets. At our lab, Kristen Scott, Bettina Berendt and I created a dataset and a few models to analyze sentiment for COVID-19 measures, like the curfew. Walter Daelemans' lab at UAntwerpen also created a cool dataset for a chatbot with frequently asked questions about the vaccination policy in Flanders, called VaccinChat.
| Model | ACC | $F_1$ |
|---|---|---|
| Domain-adapted models | ||
| BERTje+ | 77.7% | — |
| CoNTACT+ | 77.9% | — |
| General-purpose models | ||
| BERTje | 74.7% | — |
| RobBERT v2 | 74.9% | 77.2% |
| RobBERT-2022 | 76.3% | 79.3% |
RobBERT-2022 performs pretty well on both sentence classification tasks, surpassing the original RobBERT model with a few percentage points. The VaccinChat results are also pretty interesting, since the original paper also included experiments with domain-adapted models that we can compare with. There, the results of RobBERT-2022 are a bit lower than the domain-adapted models, which makes sense: RobBERT-2022 is still a general-purpose model and Corona-related text was only a small part of the training data.