Although 2023 is almost over, we do want to release an updated
RobBERT model, our Dutch BERT model. Just like last year, we release a
base model, but this time we also release an additional large model with
355M parameters (x3 over robbert-2022-base). We are particularly proud
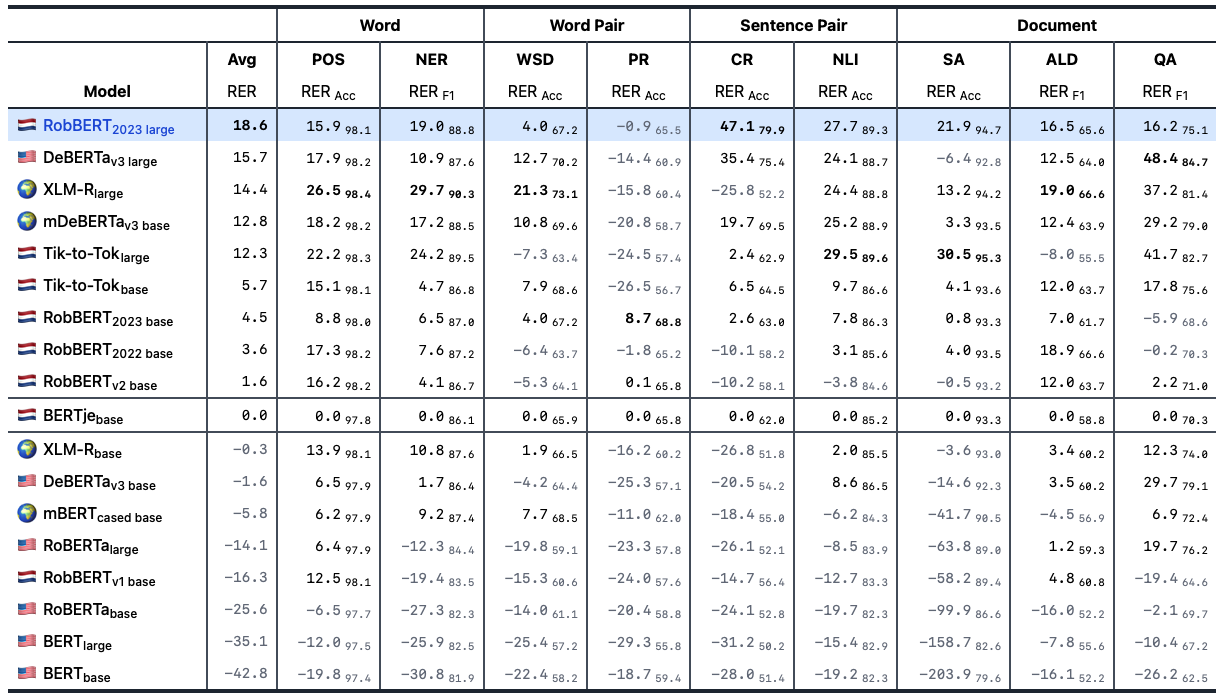
of the performance of both models, surpassing both the robbert-v2-base
and robbert-2022-base models with +2.9 and +0.9 points on the DUMB benchmark from GroNLP. In addition,
we also surpass BERTje with +18.6 points with
RobBERT-2023-large.
However, we cheated a little bit. RobBERT-2023 is actually a completely new model, unlike RobBERT-2022 that extends the original RobBERT vocab. We spend a lot of time cleaning up the vocabulary, since that contained a lot of garbage (and each garbage token takes up space in our embeddings matrix).
So we spent a lot of time cleaning up the vocabulary, but that mend that we cannot reuse the work (or rather the GPU hours) of the previous RobBERT models. That’s why we cheated. We used a method we developed this year, Tik-to-Tok, to initialize our token embeddings from the larger English models, which worked pretty well.
Token initialization
Our Tik-to-Tok method proposed in this study aims to address the challenge of training monolingual language models for low and mid-resource languages due to limited and inadequate pretraining data. The method involves adapting high-resource monolingual language models to a new target language by using a word translation dictionary that encompasses both the source and target languages. The approach maps tokens from the target tokenizer to semantically similar tokens from the source language tokenizer, improving the initialization of the embedding table for the target language. This one-to-many token mapping significantly enhances the efficiency of language adaptation, reducing the amount of data and time required for training state-of-the-art models across various downstream tasks.
To create a Dutch language model (RobBERT-2023) from RoBERTa using the Tik-to-Tok method, we replace the original tokenizer of the RoBERTa model with a new vocabulary. We cleaned created a cleaned corpus of OSCAR-2023 where we filtered out all unnecessary unicode ranges, so no more Chinese characters eating up our vocabulary. Just compare the old vocabulary with the new vocabulary, what a difference!
Results
All in all, the results are really good. We score really high on the DUMB benchmark. Note that there are also Dutch models using our Tik-To-Tok method, but the tokenizer is different. We release these models specifically as the RobBERT family, so we took some extra care to make them have a good tokenizer and good pre-training.
The future
So now we have a pretty good method to reuse language models, even when we want to introduce a new tokenizer. That’s important, since extending BPE tokenizers like we did in robbert-2022 was not exactly optimal, but language keeps changing enough that new tokens do need to be added. There are also some other issues with BPE, so it’s great to have a method to translate our RobBERT model if a better tokenizer comes along.
Acknowledgements
Thanks to Thomas Winters for creating the new 2023 logo!
This research has been funded by the Flanders AI Research Programme and FWO.

